5.5 Unsupervised Machine Learning Part 2: Additional Clustering Applications
This training module was developed by Alexis Payton, Lauren E. Koval, David M. Reif, and Julia E. Rager.
All input files (script, data, and figures) can be downloaded from the UNC-SRP TAME2 GitHub website.
Introduction to Training Module
The previous module TAME 2.0 Module 5.4 Unsupervised Machine Learning Part 1: K-Means Clustering & PCA, served as introduction to unsupervised machine learning (ML). Unsupervised ML involves training a model on a dataset lacking ground truths or response variables. However, in the previous module, the number of clusters was selected based on prior information (i.e., chemical class), but what if you’re in a situation where you don’t know how many clusters to investigate a priori? This commonly occurs, particularly in the field of environmental health research in instances when investigators want to take a more unbiased view of their data and/or do not have information that can be used to inform the optimal number of clusters to select. In these instances,unsupervised ML techniques can be very helpful, and in this module, we’ll explore the following concepts to further understand unsupervised ML:
- K-Means and hierarchical clustering
- Deriving the optimal number of clusters
- Visualizing clusters through a PCA-based plot, dendrograms, and heatmaps
- Determining each variable’s contribution to the clusters
K-Means Clustering
As mentioned in the previous module, K-means is a common clustering algorithm used to partition quantitative data. This algorithm works by first, randomly selecting a pre-specified number of clusters, k, across the data space, with each cluster having a data centroid. When using a standard Euclidean distance metric, the distance is calculated from an observation to each centroid, then the observation is assigned to the cluster of the closest centroid. After all observations have been assigned to one of the k clusters, the average of all observations in a cluster is calculated, and the centroid for the cluster is moved to the location of the mean. The process then repeats, with the distance computed between the observations and the updated centroids. Observations may be reassigned to the same cluster or moved to a different cluster if it is closer to another centroid. These iterations continue until there are no longer changes between cluster assignments for observations, resulting in the final cluster assignments that are then carried forward for analysis/interpretation.
Helpful resources on k-means clustering include the following: The Elements of Statistical Learning & Towards Data Science.
Hierarchical Clustering
Hierarchical clustering groups objects into clusters by repetitively joining similar observations until there is one large cluster (aka agglomerative or bottom-up) or repetitively splitting one large cluster until each observation stands alone (aka divisive or top-down). Regardless of whether agglomerative or divisive hierarchical clustering is used, the results can be visually represented in a tree-like figure called a dendrogram. The dendrogram below is based on the USArrests dataset available in R. The datset contains statistics on violent crimes rates (murder, assault, and rape) per capita (per 100,000 residents) for each state in the United States in 1973. For more information on the USArrests dataset, check out its associated RDocumentation.
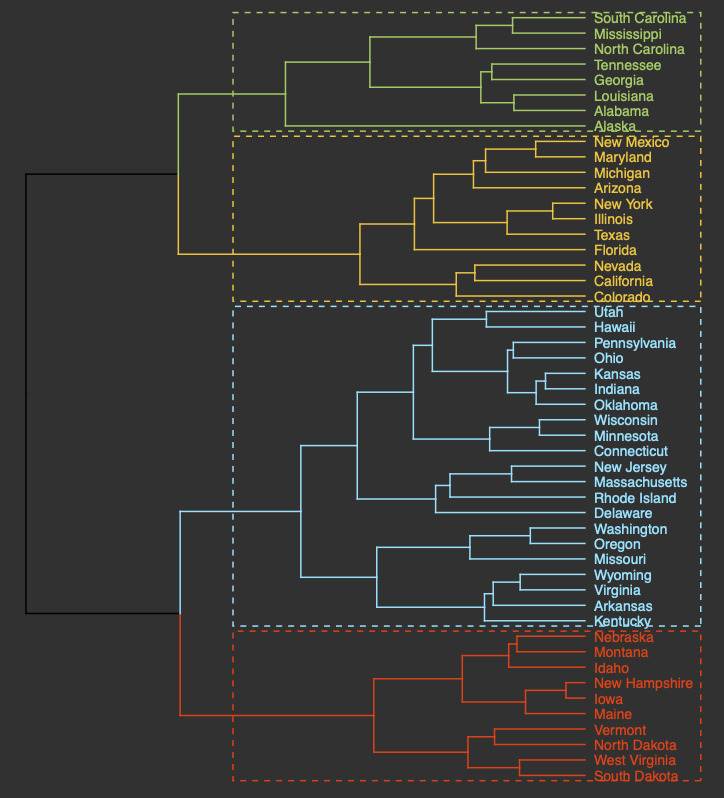
An appropriate title for this figure could be:
“Figure X. Hierarchical clustering of states based on violent crime. The dendogram uses violent crime data including murder, assault, and rape rates per 100,000 residents for each state in 1973.”
Takeaways from this dendogram:
- The 50 states can be grouped into 4 clusters based on violent crime statistics from 1973
- The dendogram can only show us clusters of states but not the data trends that led to the clustering patterns that we see. Yes, it is useful to know what states have similar violent crime patterns overall, but it is important to pinpoint the variables (ie. murder, assault, and rape) that are responsible for the clustering patterns we’re seeing. This idea will be explored later in the module with an environmentally-relevant dataset.
Going back to hiearchical clustering, during the repetitive splitting or joining of observations, the similarity between existing clusters is calculated after each iteration. This value informs the formation of subsequent clusters. Different methods, or linkage functions, can be considered when calculating this similarity, particularly for agglomerative clustering which is often the preferred approach. Some example methods include:
- Complete Linkage: the maximum distance between two data points located in separate clusters.
- Single Linkage: the minimum distance between two data points located in separate clusters.
- Average Linkage: the average pairwise distance between all pairs of data points in separate clusters.
- Centroid Linkage: the distance between the centroids or centers of each cluster.
- Ward Linkage: seeks to minimize the variance between clusters.
Each method has its advantages and disadvantages and more information on all distance calculations between clusters can be found at the following resource: Hierarchical Clustering.
Deriving the Optimal Number of Clusters
Before clustering can be performed, the function needs to be informed of the number of clusters to group the objects into. In the previous module, an example was explored to see if k-means clustering would group the chemicals similarly to their chemical class (either a PFAS or statin). Therefore, we told the k-means function to cluster into 2 groups. In situations where there is little to no prior knowledge regarding the “correct” number of clusters to specify, methods exist for deriving the optimal number of clusters. Three common methods to find the optimal k, or number of clusters, for both k-means and hierarchical clustering include: the elbow method, silhouette method, and the gap statistic method. These techniques help us in determining the optimal k using visual inspection.
- Elbow Method: uses a plot of the within cluster sum of squares (WCSS) on the y axis and different values of k on the x axis. The location where we no longer observe a significant reduction in WCSS, or where an “elbow” can be seen, is the optimal k value. As we can see, after a certain point, having more clusters does not lead to a significant reduction in WCSS.
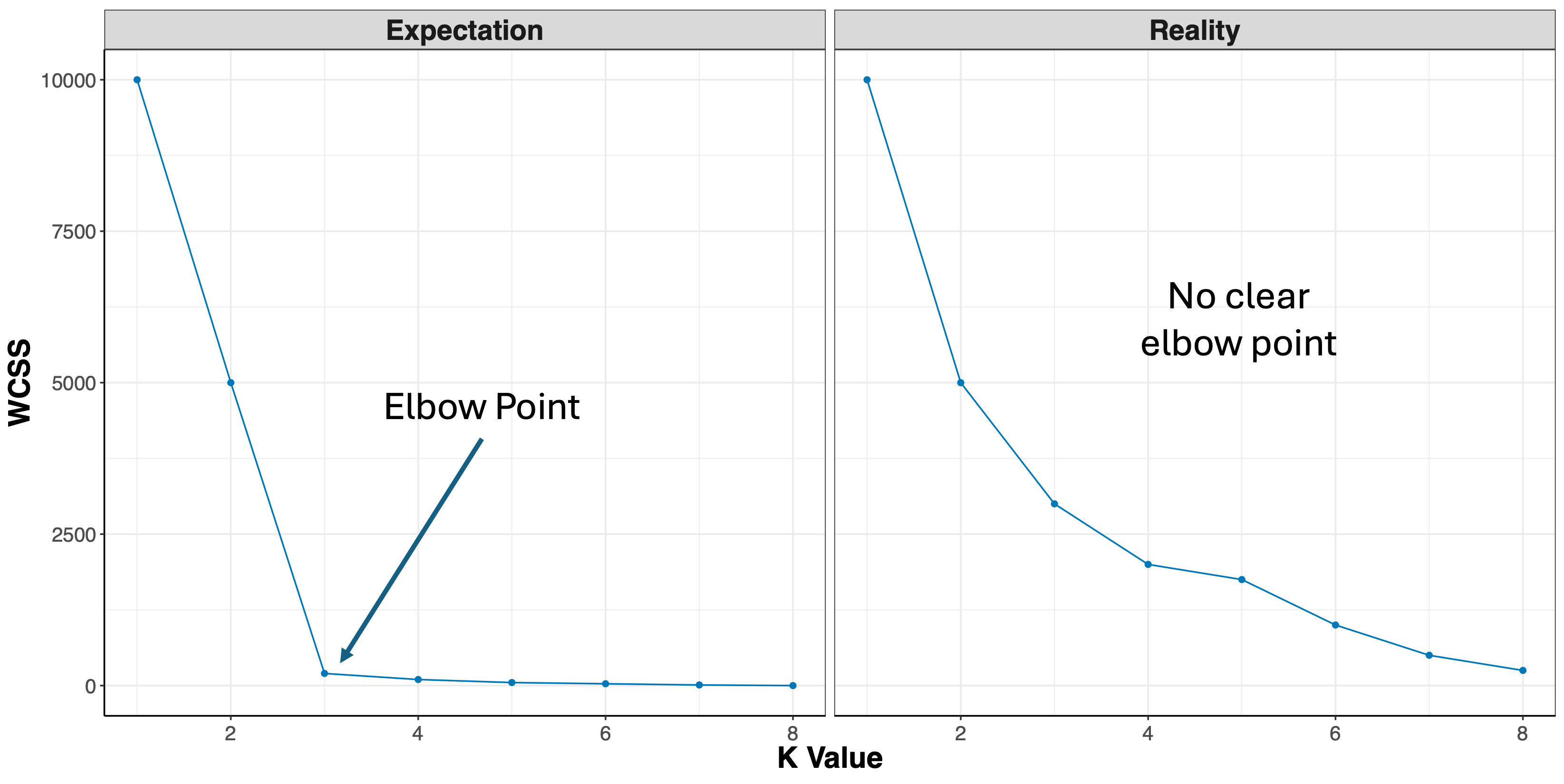
Looking at the figures above, the elbow point is much clearer in the first plot versus the second, however, elbow curves from real-world datasets typically resemble the second figure. This is why it’s recommended to consider more than one method to determine the optimal number of clusters.
- Silhouette Method: uses a plot of the average silhouette width (score) on the y axis and different values of k on the x axis. The silhouette score is measure of each object’s similarity to its own cluster and how dissimilar it is to other clusters. The location where the average silhouette width is maximized is the optimal k value.
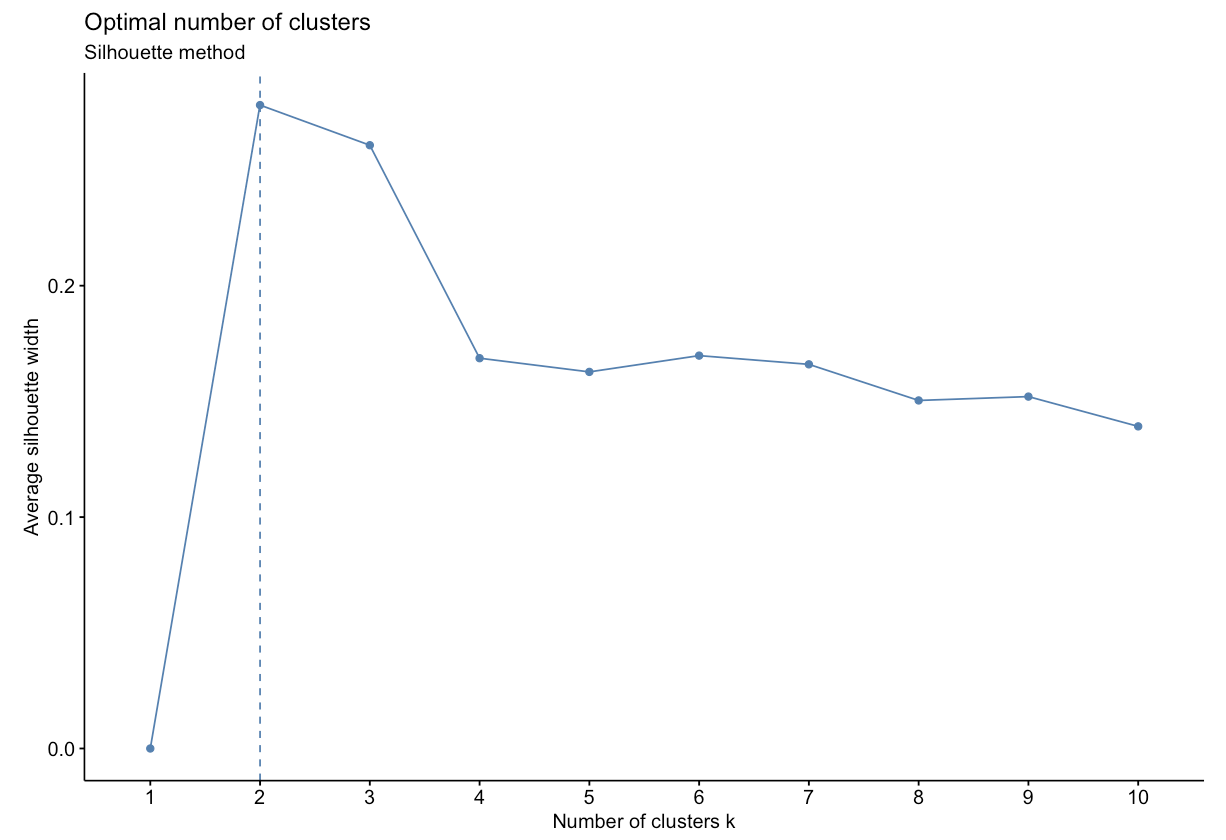
Based on the figure above, the optimal number of clusters is 2 using the silhouette method.
- Gap Statistic Method: uses a plot of the gap statistic on the y axis and different values of k on the x axis. The gap statistic evaluates the intracluster variation in comparison to expected values derived from a Monte Carlo generated, null reference data distribution for varying values of k. The optimal number of clusters is the smallest value where the gap statistic of k is greater than or equal to the gap statistic of k+1 minus the standard deviation of k+1. More details can be found here.
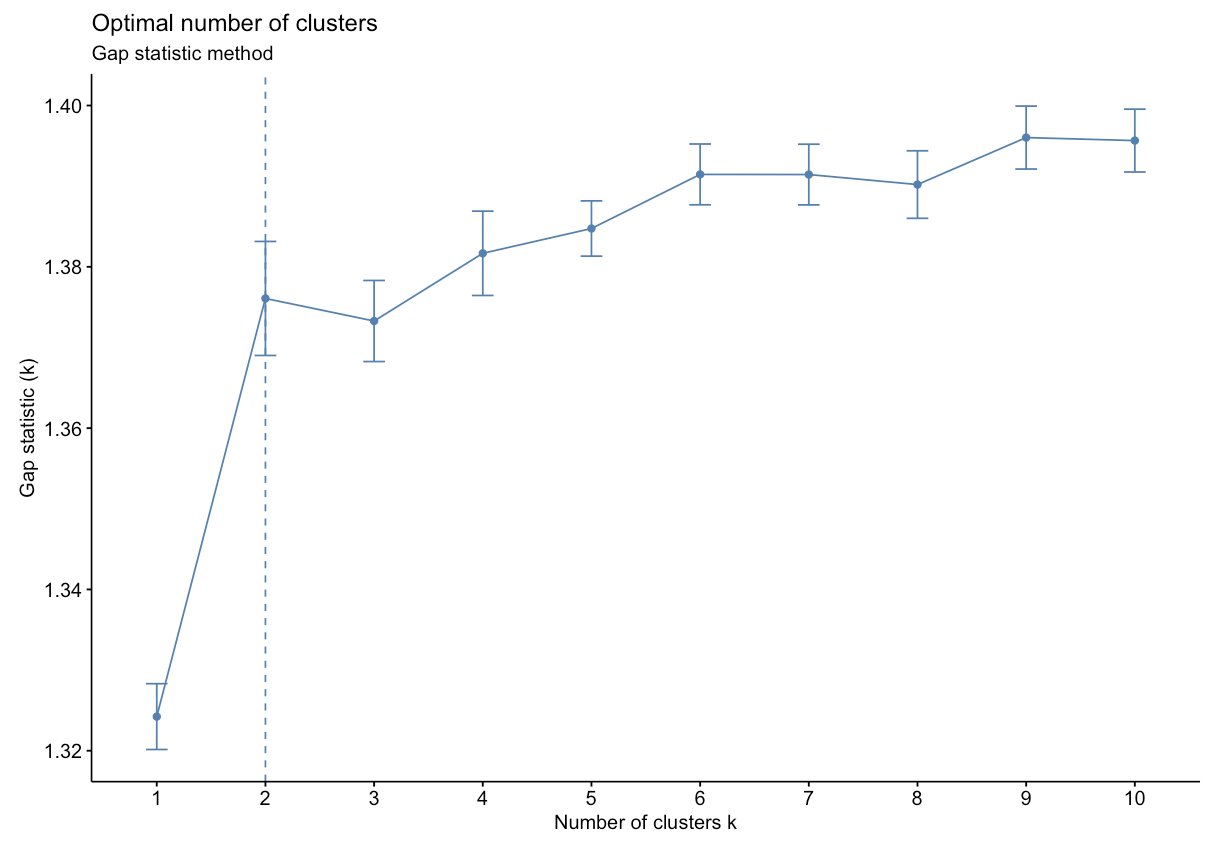
Based on the figure above, the optimal number of clusters is 2 using the gap statistic method.
For additional information and code on all three methods, check out Determining the Optimal Number of Clusters: 3 Must Know Methods. It is also worth mentioning that while these methods are useful, further interpreting the result in the context of your problem can be beneficial, for example, checking whether clusters make biological sense when working with a genomic dataset.
Introduction to Example Data
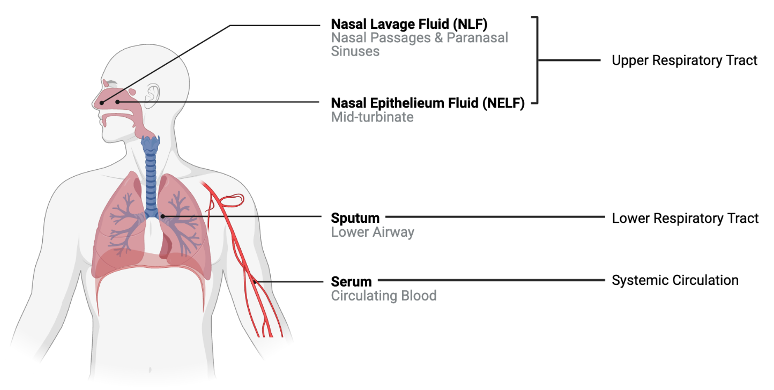
We will apply these techniques using an example dataset from a previously published study where 22 cytokine concentrations were derived from 44 subjects with varying smoking statuses (14 non-smokers, 17 e-cigarette users, and 13 cigarette smokers) from 4 different sampling regions in the body. These samples were derived from nasal lavage fluid (NLF), nasal epithelieum fluid (NELF), sputum, and serum as pictured below. Samples were taken from different regions in the body to compare cytokine expression in the upper respiratory tract, lower respiratory tract, and systemic circulation.
A research question that we had was “Does cytokine expression change based on a subject’s smoking habits? If so, does cigarette smoke or e-cigarette vapor induce cytokine suppression or proliferation?” Traditionally these questions would have been answered by analyzing each biomarker individually using a two-group comparison test like a t test (which we completed in this study). However, biomarkers do not work in isolation in the body, suggesting that individual biomarker statistical approaches may not capture the full biological responses occurring. Therefore we used a clustering approach to group cytokines as an attempt to more closely simulate interactions that occur in vivo. From there, statistical tests were run to assess the effects of smoking status on each cluster.
For the purposes of this training exercise, we will focus solely on the nasal epithelieum lining fluid, or NELF, samples. In addition, we’ll use k-means and hierarchical clustering to compare how cytokines cluster at baseline. Full methods are further described in the publication below:
- Payton AD, Perryman AN, Hoffman JR, Avula V, Wells H, Robinette C, Alexis NE, Jaspers I, Rager JE, Rebuli ME. Cytokine signature clusters as a tool to compare changes associated with tobacco product use in upper and lower airway samples. American Journal of Physiology-Lung Cellular and Molecular Physiology 2022 322:5, L722-L736. PMID: 35318855
Let’s read in and view the dataset we’ll be working with.
Script Preparations
Installing required R packages
If you already have these packages installed, you can skip this step, or you can run the below code which checks installation status for you
if (!requireNamespace("vegan"))
install.packages("vegan");
if (!requireNamespace("ggrepel"))
install.packages("ggrepel");
if (!requireNamespace("dendextend"))
install.packages("dendextend");
if (!requireNamespace("ggsci"))
install.packages("ggsci");
if (!requireNamespace("FactoMineR"))
install.packages("FactoMineR");Loading required R packages
## Warning: package 'vegan' was built under R version 4.5.2## Warning: package 'permute' was built under R version 4.5.2## Warning: package 'ggrepel' was built under R version 4.5.2Importing example dataset
Then let’s read in our example dataset. As mentioned in the introduction, this example dataset contains cytokine concentrations derived from 44 subjects. Let’s import and view these data:
# Reading in file
cytokines_df <- data.frame(read_excel("Chapter_5/5_5_Unsupervised_ML_2/5_5_Unsupervised_ML_2_Data.xlsx", sheet = 2))
# Viewing data
head(cytokines_df)## Original_Identifier Group SubjectNo SubjectID Compartment Protein Conc
## 1 E_C_F_002 NS 1 NS_1 NELF IFNg 17.642316
## 2 E_C_F_002 NS 1 NS_1 NELF IL10 2.873724
## 3 E_C_F_002 NS 1 NS_1 NELF IL12p70 1.625272
## 4 E_C_F_002 NS 1 NS_1 NELF IL13 36.117692
## 5 E_C_F_002 NS 1 NS_1 NELF IL1b 104.409217
## 6 E_C_F_002 NS 1 NS_1 NELF IL6 21.159536
## Conc_pslog2
## 1 4.220509
## 2 1.953721
## 3 1.392467
## 4 5.214035
## 5 6.719857
## 6 4.469856These data contain the following information:
Original_Identifier: initial identifier given to each subject by our wet bench colleaguesGroup: denotes the smoking status of the subject (“NS” = “non-smoker”, “Ecig” = “E-cigarette user”, “CS” = “cigarette smoker”)SubjectNo: ordinal subject number assigned to each subject after the dataset was wrangled (1-44)SubjectID: unique subject identifier that combines the group and subject numberCompartment: region of the body from which the sample was taken (“NLF” = “nasal lavage fluid sample”, “NELF” = “nasal epithelieum lining fluid sample”, “Sputum” = “induced sputum sample”, “Serum” = “blood serum sample”)Protein: cytokine nameConc: concentration (pg/mL)Conc_pslog2: psuedo-log2 concentration
Now that the data has been read in, we can start by asking some initial questions about the data.
Training Module’s Environmental Health Questions
This training module was specifically developed to answer the following environmental health questions:
- What is the optimal number of clusters the cytokines can be grouped into that were derived from nasal epithelium fluid (NELF) in non-smokers using k-means clustering?
- After selecting a cluster number, which cytokines were assigned to each k-means cluster?
- What is the optimal number of clusters the cytokines can be grouped into that were derived from nasal epithelium fluid (NELF) in non-smokers using hierarchical clustering?
- How do the hierarchical cluster assignments compare to the k-means cluster assignments?
- Which cytokines have the greatest contributions to the first two eigenvectors?
To answer the first environmental health question, let’s start by filtering to include only NELF derived samples and non-smokers.
## Original_Identifier Group SubjectNo SubjectID Compartment Protein Conc
## 1 E_C_F_002 NS 1 NS_1 NELF IFNg 17.642316
## 2 E_C_F_002 NS 1 NS_1 NELF IL10 2.873724
## 3 E_C_F_002 NS 1 NS_1 NELF IL12p70 1.625272
## 4 E_C_F_002 NS 1 NS_1 NELF IL13 36.117692
## 5 E_C_F_002 NS 1 NS_1 NELF IL1b 104.409217
## 6 E_C_F_002 NS 1 NS_1 NELF IL6 21.159536
## Conc_pslog2
## 1 4.220509
## 2 1.953721
## 3 1.392467
## 4 5.214035
## 5 6.719857
## 6 4.469856The functions we use will require us to cast the data wider. We will accomplish this using the dcast() function from the reshape2 package.
wider_baseline_df <- reshape2::dcast(baseline_df, Protein ~ SubjectID, value.var = "Conc_pslog2") %>%
column_to_rownames("Protein")
head(wider_baseline_df)## NS_1 NS_10 NS_11 NS_12 NS_13 NS_14
## Eotaxin 7.215729 8.016193 6.264252 6.938344 5.152683 7.937892
## Eotaxin3 4.396783 4.006488 5.289509 3.597945 3.051951 3.063025
## Fractalkine 13.584554 13.679882 12.952220 13.464652 12.110742 12.785656
## I309 0.000000 0.000000 0.000000 0.000000 0.000000 1.617372
## IFNg 4.220509 1.990018 2.656691 3.439682 2.318340 3.439850
## IL10 1.953721 1.145162 1.348623 1.801954 1.176498 1.800412
## NS_2 NS_3 NS_4 NS_5 NS_6 NS_7
## Eotaxin 9.773407 6.12290913 5.758602 4.19868540 6.832578 7.998467
## Eotaxin3 9.022390 2.50161364 2.721195 2.21084320 3.820379 5.549164
## Fractalkine 14.961872 12.71538464 12.057105 10.38711624 12.917180 14.636190
## I309 1.103140 0.00000000 0.000000 0.00000000 0.000000 0.000000
## IFNg 4.394705 0.00000000 2.638213 0.04830196 1.914092 3.251501
## IL10 2.652120 0.08945805 2.020155 0.84649523 1.119272 2.007941
## NS_8 NS_9
## Eotaxin 9.242464 7.127746
## Eotaxin3 13.724108 3.553097
## Fractalkine 14.047382 13.146599
## I309 0.000000 0.000000
## IFNg 4.104820 2.940248
## IL10 2.576814 1.970627Now we can derive clusters using the fviz_nbclust() function to determine the optimal k based on suggestions from the elbow, silhouette, and gap statistic methods. We can use this code for both k-means and hierarchical clustering by changing the FUNcluster parameter. Lets start with k-means:.
# Elbow method
fviz_nbclust(wider_baseline_df, FUNcluster = kmeans, method = "wss") +
labs(subtitle = "Elbow method") 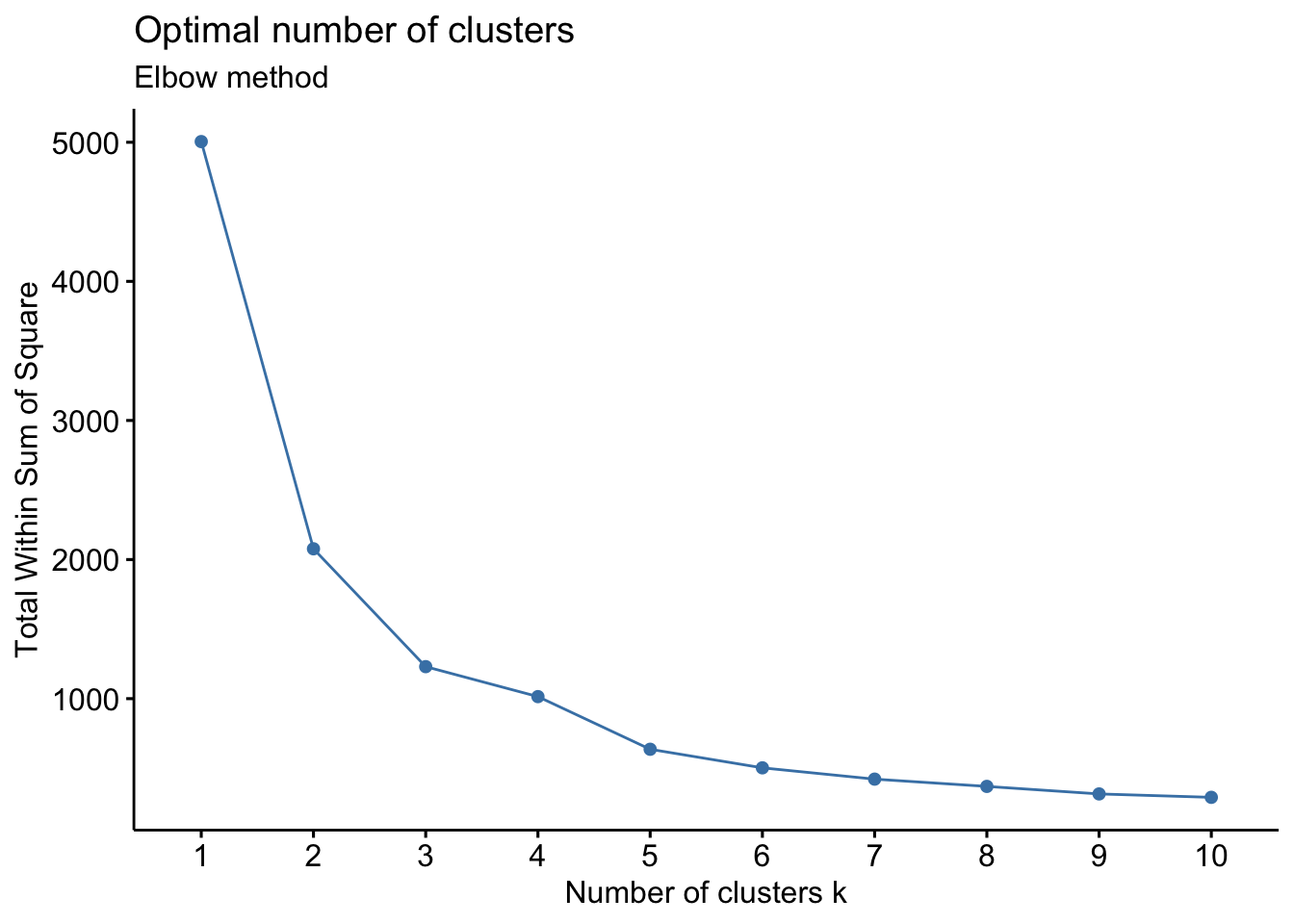
# Silhouette method
fviz_nbclust(wider_baseline_df, FUNcluster = kmeans, method = "silhouette") +
labs(subtitle = "Silhouette method") 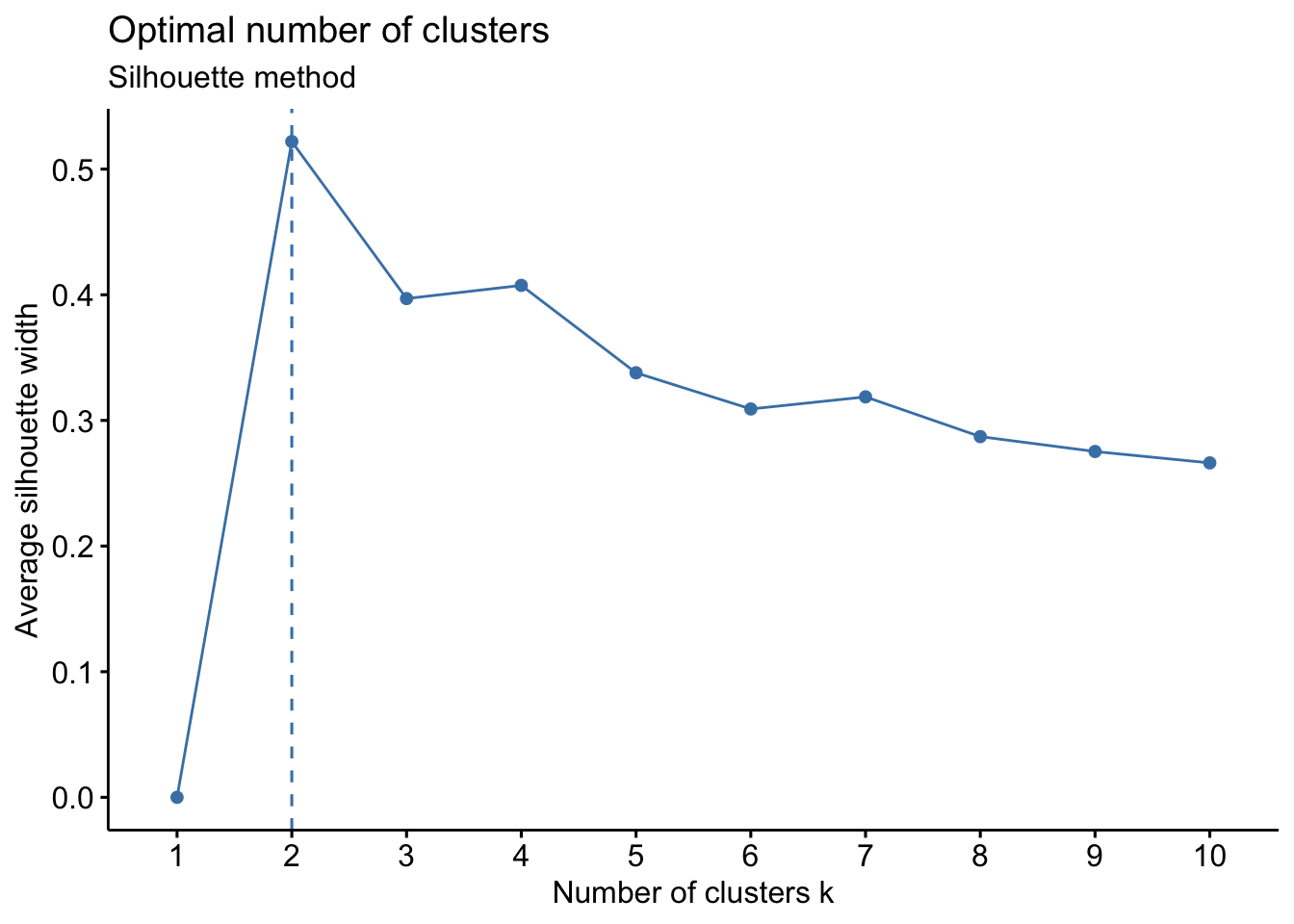
# Gap statistic method
fviz_nbclust(wider_baseline_df, FUNcluster = kmeans, method = "gap_stat") +
labs(subtitle = "Gap Statisitc method") ## Warning: `aes_string()` was deprecated in ggplot2 3.0.0.
## ℹ Please use tidy evaluation idioms with `aes()`.
## ℹ See also `vignette("ggplot2-in-packages")` for more information.
## ℹ The deprecated feature was likely used in the factoextra package.
## Please report the issue at <https://github.com/kassambara/factoextra/issues>.
## This warning is displayed once per session.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.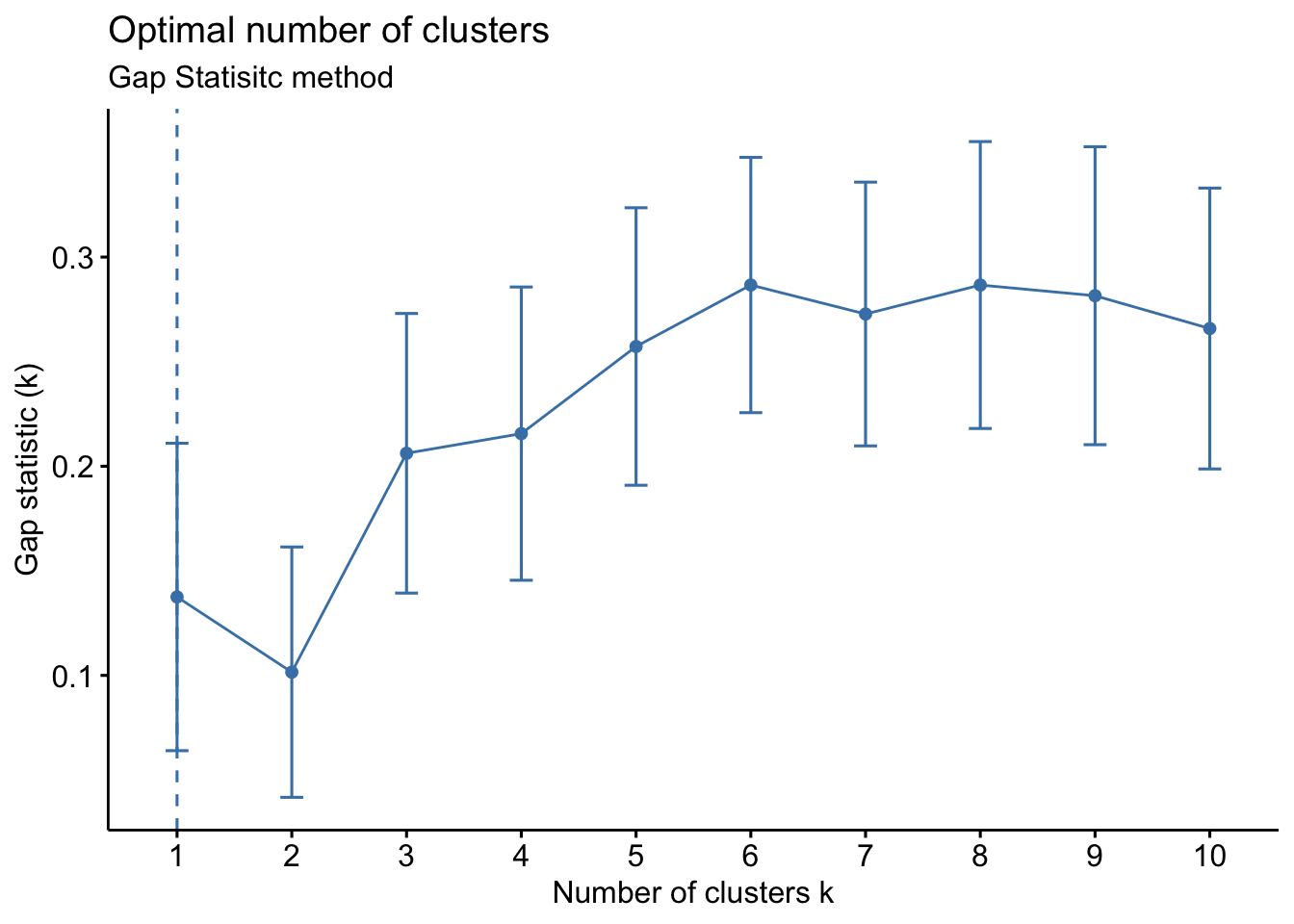
The elbow method is suggesting 2 or 3 clusters, the silhouette method is suggesting 2, and the gap statistic method is suggesting 1. Since each of these methods is recommending different k values, we can go ahead and run k-means to visualize the clusters and test those different k’s. K-means clusters will be visualized using the fviz_cluster() function.
# Choosing to iterate through 2 or 3 clusters using i as our iterator
for (i in 2:3){
# nstart = number of random starting partitions, it's recommended for nstart > 1
cluster_k <- kmeans(wider_baseline_df, centers = i, nstart = 25)
cluster_plot <- fviz_cluster(cluster_k, data = wider_baseline_df) + ggtitle(paste0("k = ", i))
print(cluster_plot)
}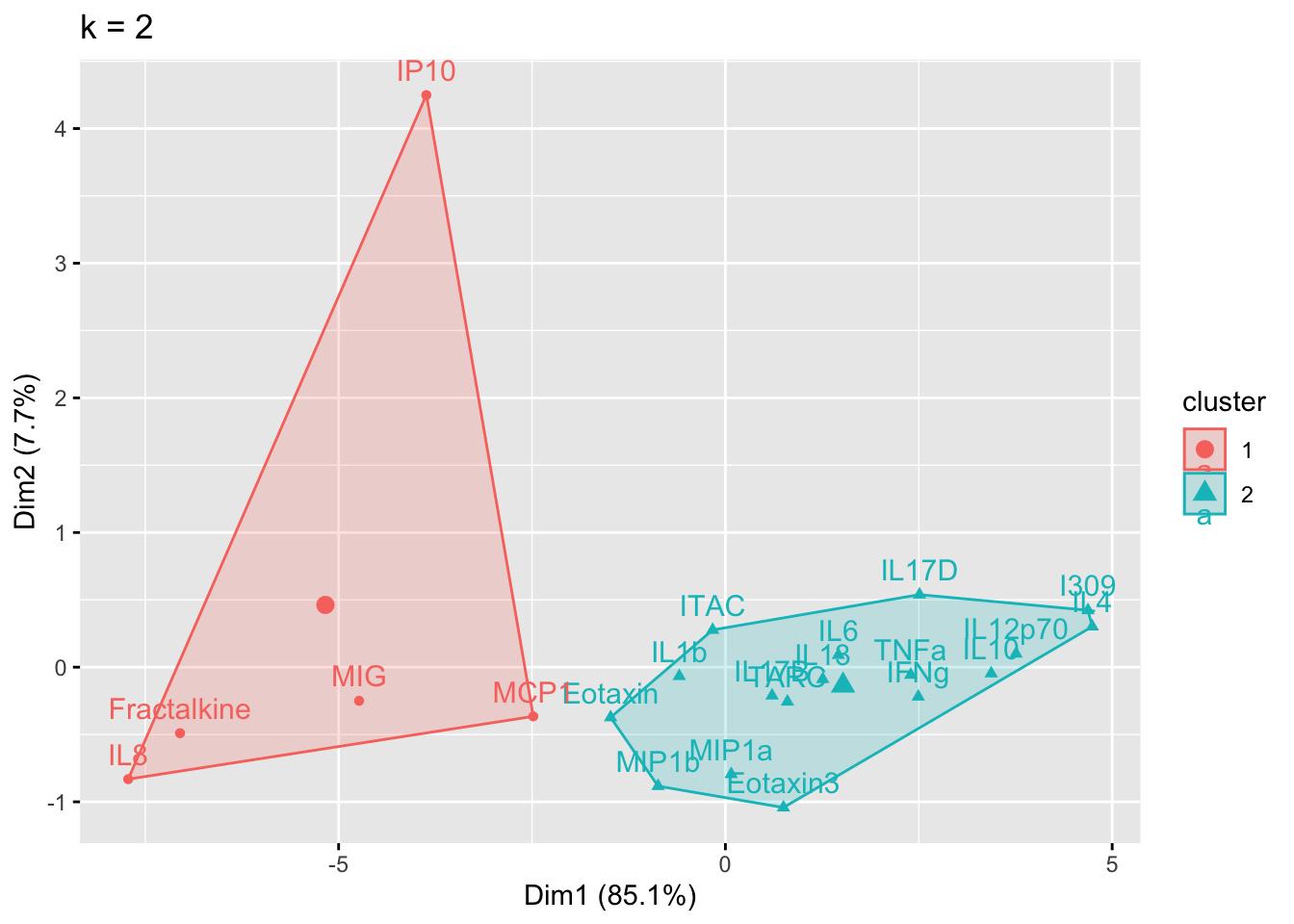
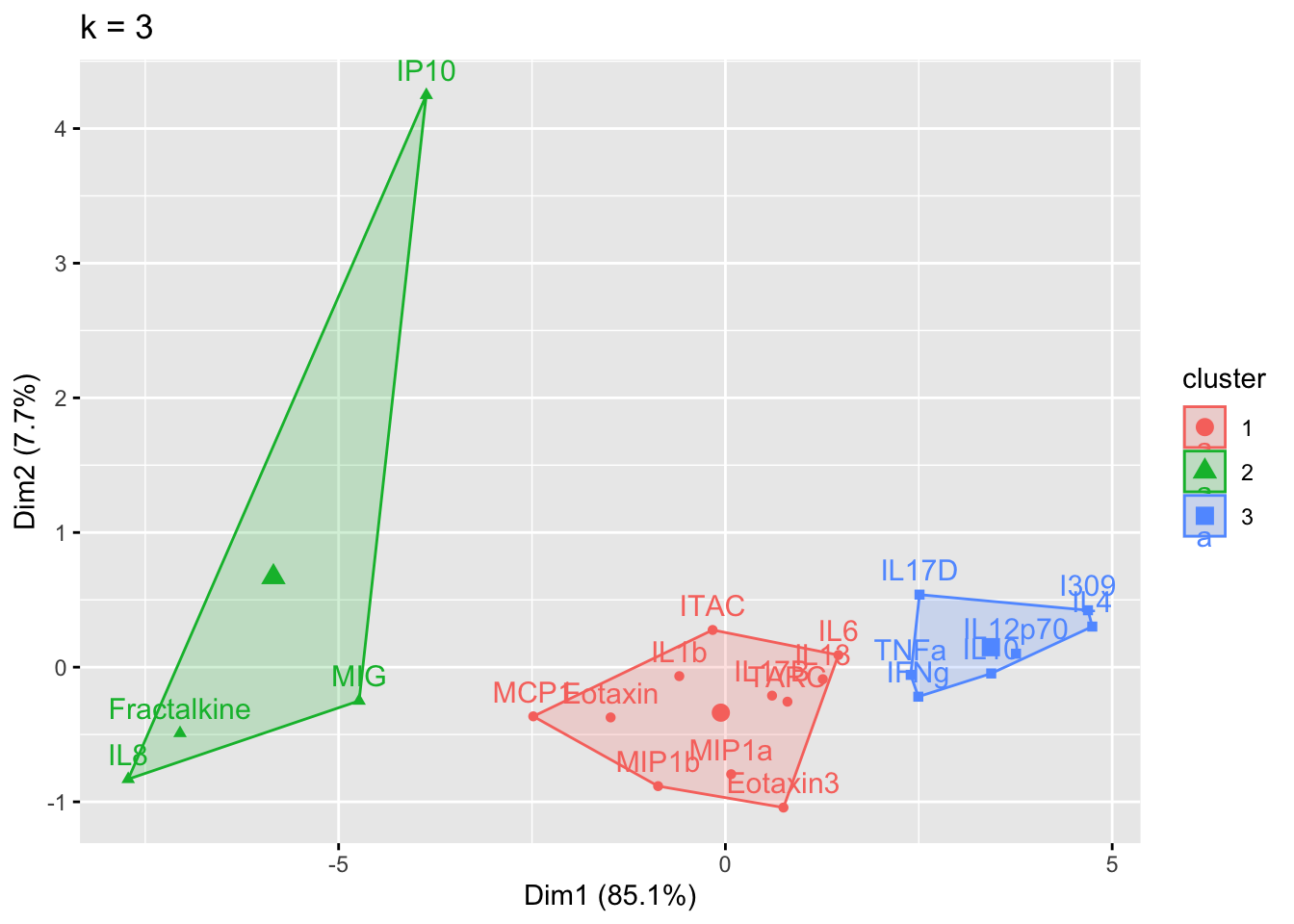
Answer to Environmental Health Question 1
With this, we can answer Environmental Health Question #1: What is the optimal number of clusters the cytokines can be grouped into that were derived from nasal epithelium fluid (NELF) in non-smokers using k-means clustering?
Answer: 2 or 3 clusters can be justified here, based on using the elbow or silhouette method or if k-means happens to group cytokines together that were implicated in similar biological pathways. In the final paper, we moved forward with 3 clusters, because it was justifiable from the methods and provided more granularity in the clusters.
The final cluster assignments can easily be obtained using the kmeans() function from the stats package.
cluster_kmeans_3 <- kmeans(wider_baseline_df, centers = 3, nstart = 25)
cluster_kmeans_df <- data.frame(cluster_kmeans_3$cluster) %>%
rownames_to_column("Cytokine") %>%
rename(`K-Means Cluster` = cluster_kmeans_3.cluster) %>%
# Ordering the dataframe for easier comparison
arrange(`K-Means Cluster`)
cluster_kmeans_df## Cytokine K-Means Cluster
## 1 Fractalkine 1
## 2 IL8 1
## 3 IP10 1
## 4 MIG 1
## 5 Eotaxin 2
## 6 Eotaxin3 2
## 7 IL13 2
## 8 IL17B 2
## 9 IL1b 2
## 10 IL6 2
## 11 ITAC 2
## 12 MCP1 2
## 13 MIP1a 2
## 14 MIP1b 2
## 15 TARC 2
## 16 I309 3
## 17 IFNg 3
## 18 IL10 3
## 19 IL12p70 3
## 20 IL17D 3
## 21 IL4 3
## 22 TNFa 3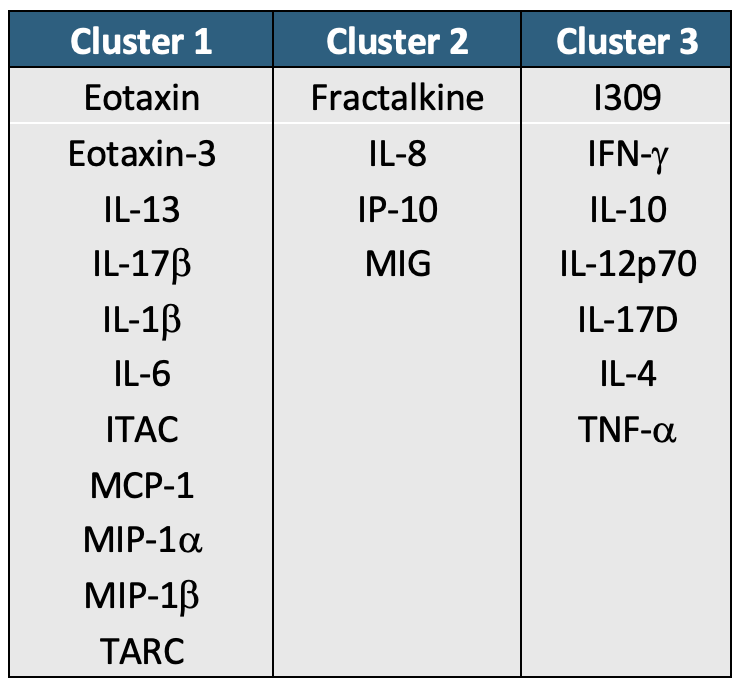
Hierarchical Clustering
Next, we’ll turn our attention to answering environmental health questions 3 and 4: What is the optimal number of clusters the cytokines can be grouped into that were derived from nasal epithelium fluid (NELF) in non-smokers using hierarchical clustering? How do the hierarchical cluster assignments compare to the k-means cluster assignments?
Just as we used the elbow method, silhouette profile, and gap statistic to determine the optimal number of clusters for k-means, we can leverage the same approaches for hierarchical by changing the FUNcluster parameter.
# Elbow method
fviz_nbclust(wider_baseline_df, FUNcluster = hcut, method = "wss") +
labs(subtitle = "Elbow method") 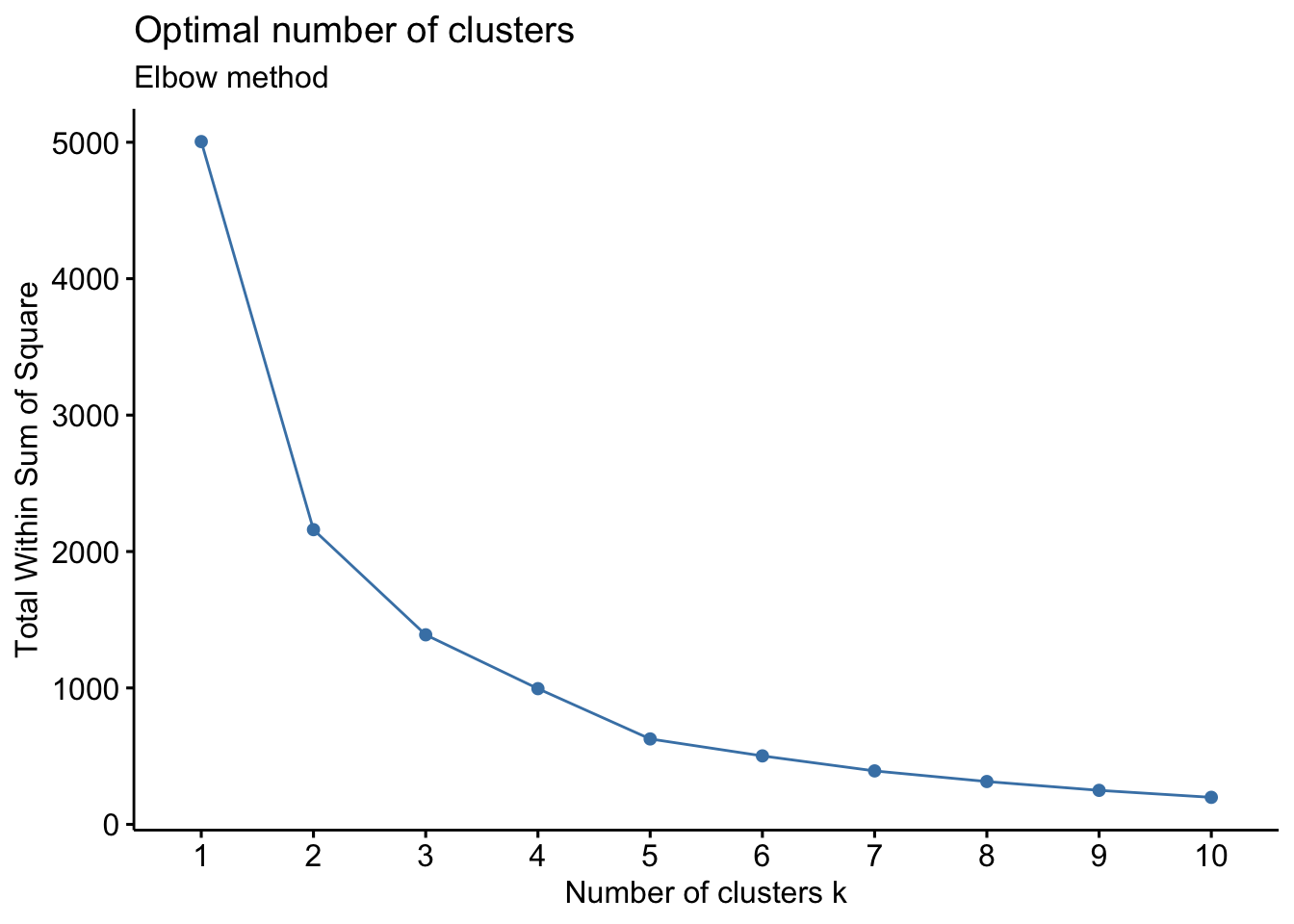
# Silhouette method
fviz_nbclust(wider_baseline_df, FUNcluster = hcut, method = "silhouette") +
labs(subtitle = "Silhouette method") 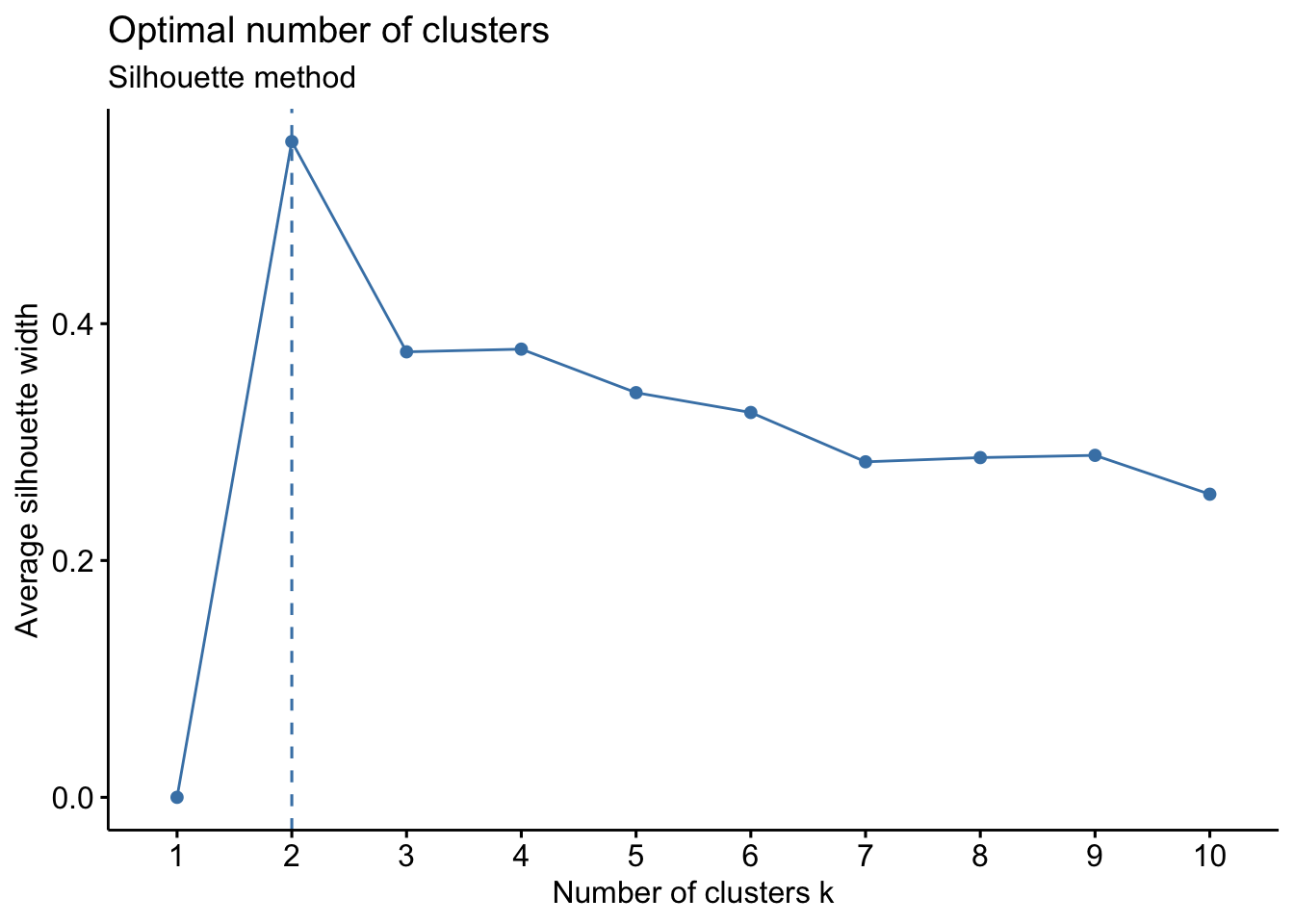
# Gap statistic method
fviz_nbclust(wider_baseline_df, FUNcluster = hcut, method = "gap_stat") +
labs(subtitle = "Gap Statisitc method") 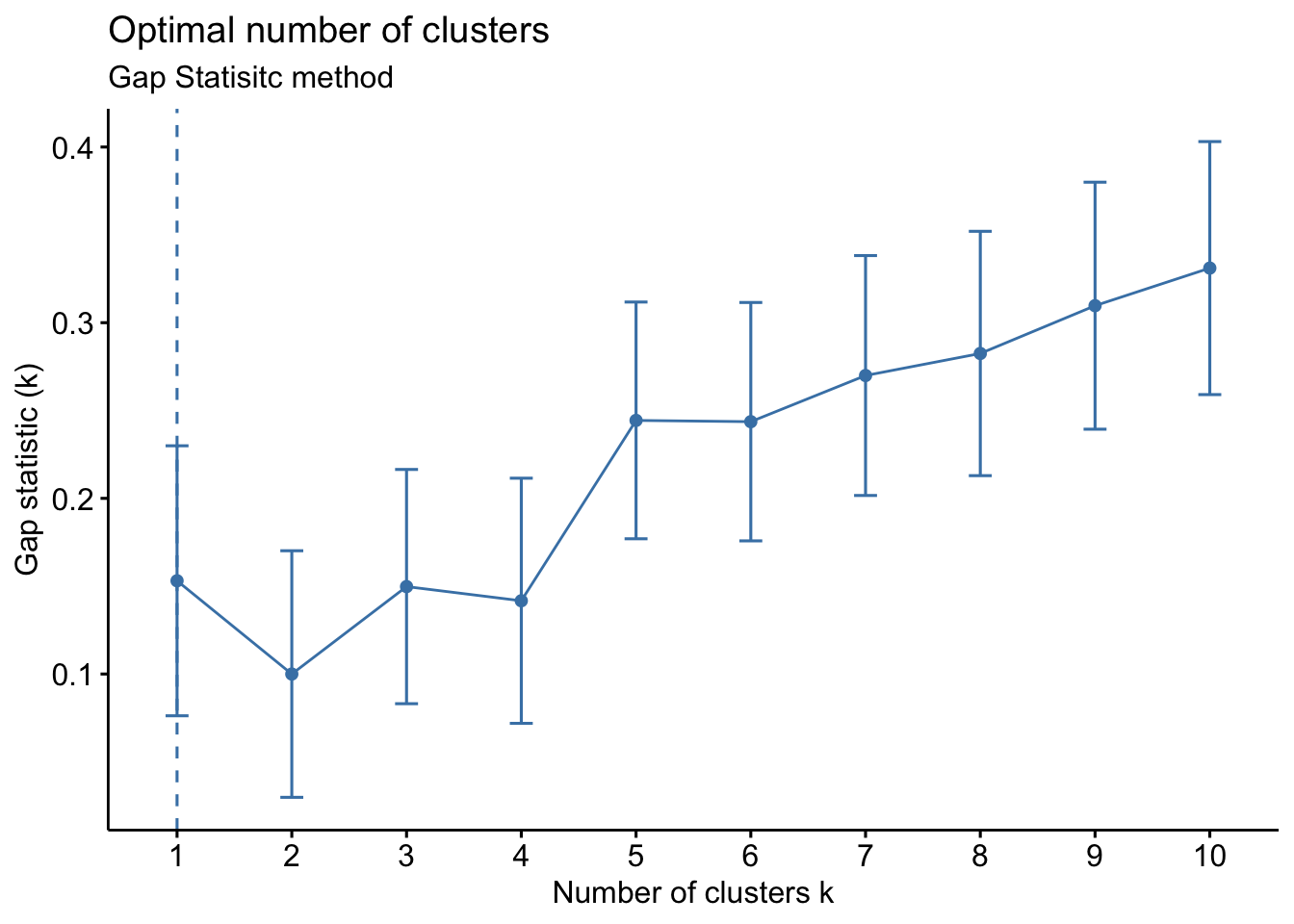 We can see the results are quite similar with 2-3 clusters appearing optimal.
We can see the results are quite similar with 2-3 clusters appearing optimal.
Answer to Environmental Health Question 3
With this, we can answer Environmental Health Question #3: What is the optimal number of clusters the cytokines can be grouped into that were derived from nasal epithelium fluid (NELF) in non-smokers using hierarchical clustering?
Answer: Again, 2 or 3 clusters can be justified here, but for the same reasons mentioned for the first environmental health question, we landed on 3 clusters.
Now we can perform the clustering and visualize and extract the results. We’ll start by using the dist() function to calculate the euclidean distance between the clusters followed by the hclust() function to obtain the hierarchical clustering assignments.
## NS_1 NS_10 NS_11 NS_12 NS_13 NS_14
## Eotaxin 7.215729 8.016193 6.264252 6.938344 5.152683 7.937892
## Eotaxin3 4.396783 4.006488 5.289509 3.597945 3.051951 3.063025
## Fractalkine 13.584554 13.679882 12.952220 13.464652 12.110742 12.785656
## I309 0.000000 0.000000 0.000000 0.000000 0.000000 1.617372
## IFNg 4.220509 1.990018 2.656691 3.439682 2.318340 3.439850
## IL10 1.953721 1.145162 1.348623 1.801954 1.176498 1.800412
## NS_2 NS_3 NS_4 NS_5 NS_6 NS_7
## Eotaxin 9.773407 6.12290913 5.758602 4.19868540 6.832578 7.998467
## Eotaxin3 9.022390 2.50161364 2.721195 2.21084320 3.820379 5.549164
## Fractalkine 14.961872 12.71538464 12.057105 10.38711624 12.917180 14.636190
## I309 1.103140 0.00000000 0.000000 0.00000000 0.000000 0.000000
## IFNg 4.394705 0.00000000 2.638213 0.04830196 1.914092 3.251501
## IL10 2.652120 0.08945805 2.020155 0.84649523 1.119272 2.007941
## NS_8 NS_9
## Eotaxin 9.242464 7.127746
## Eotaxin3 13.724108 3.553097
## Fractalkine 14.047382 13.146599
## I309 0.000000 0.000000
## IFNg 4.104820 2.940248
## IL10 2.576814 1.970627# First scaling data with each subject (down columns)
scaled_df <- data.frame(apply(wider_baseline_df, 2, scale))
rownames(scaled_df) = rownames(wider_baseline_df)
head(scaled_df)## NS_1 NS_10 NS_11 NS_12 NS_13 NS_14
## Eotaxin 0.1563938 0.5913460 0.20280481 0.3812918 0.04218372 0.3889166
## Eotaxin3 -0.4836295 -0.3751558 -0.03031899 -0.4135856 -0.51644074 -0.7745030
## Fractalkine 1.6023933 1.9565250 1.80232784 1.9342844 1.89246390 1.5458678
## I309 -1.4818900 -1.3408820 -1.29538062 -1.2697485 -1.32801259 -1.1195175
## IFNg -0.5236512 -0.8612069 -0.65999509 -0.4512458 -0.71152186 -0.6845711
## IL10 -1.0383105 -1.0648515 -0.97283813 -0.8409577 -1.01515934 -1.0758338
## NS_2 NS_3 NS_4 NS_5 NS_6 NS_7
## Eotaxin 0.5142129 0.5748344 0.3352251 0.1297382 0.6605088 0.4509596
## Eotaxin3 0.3434700 -0.3390521 -0.4516462 -0.3710044 -0.1481961 -0.1213017
## Fractalkine 1.6938060 2.2385415 1.9669167 1.6886200 2.2940816 2.0018134
## I309 -1.4569648 -0.9703707 -1.1565995 -0.9279215 -1.1738781 -1.4178220
## IFNg -0.7086302 -0.9703707 -0.4731435 -0.9157541 -0.6599894 -0.6581332
## IL10 -1.1048056 -0.9477947 -0.6332576 -0.7146872 -0.8733797 -0.9486817
## NS_8 NS_9
## Eotaxin 0.5504372 0.6258899
## Eotaxin3 1.4999690 -0.3063521
## Fractalkine 1.5684615 2.1955622
## I309 -1.4077759 -1.2329735
## IFNg -0.5380823 -0.4661787
## IL10 -0.8618228 -0.7190487The dist() function is initially used to calculate the Euclidean distance between each cytokine. Next, the hclust() function is used to run the hierarchical clustering analysis using the complete method by default. The method can be changed in the function using the method parameter.
# Calculating euclidean dist
dist_matrix <- dist(scaled_df, method = 'euclidean')
# Hierarchical clustering
cytokines_hc <- hclust(dist_matrix)Now we can generate a dendrogram to help us evaluate the results using the fviz_dend() function from the factoextra package. We use k=3 to be consistent with the k-means analysis.
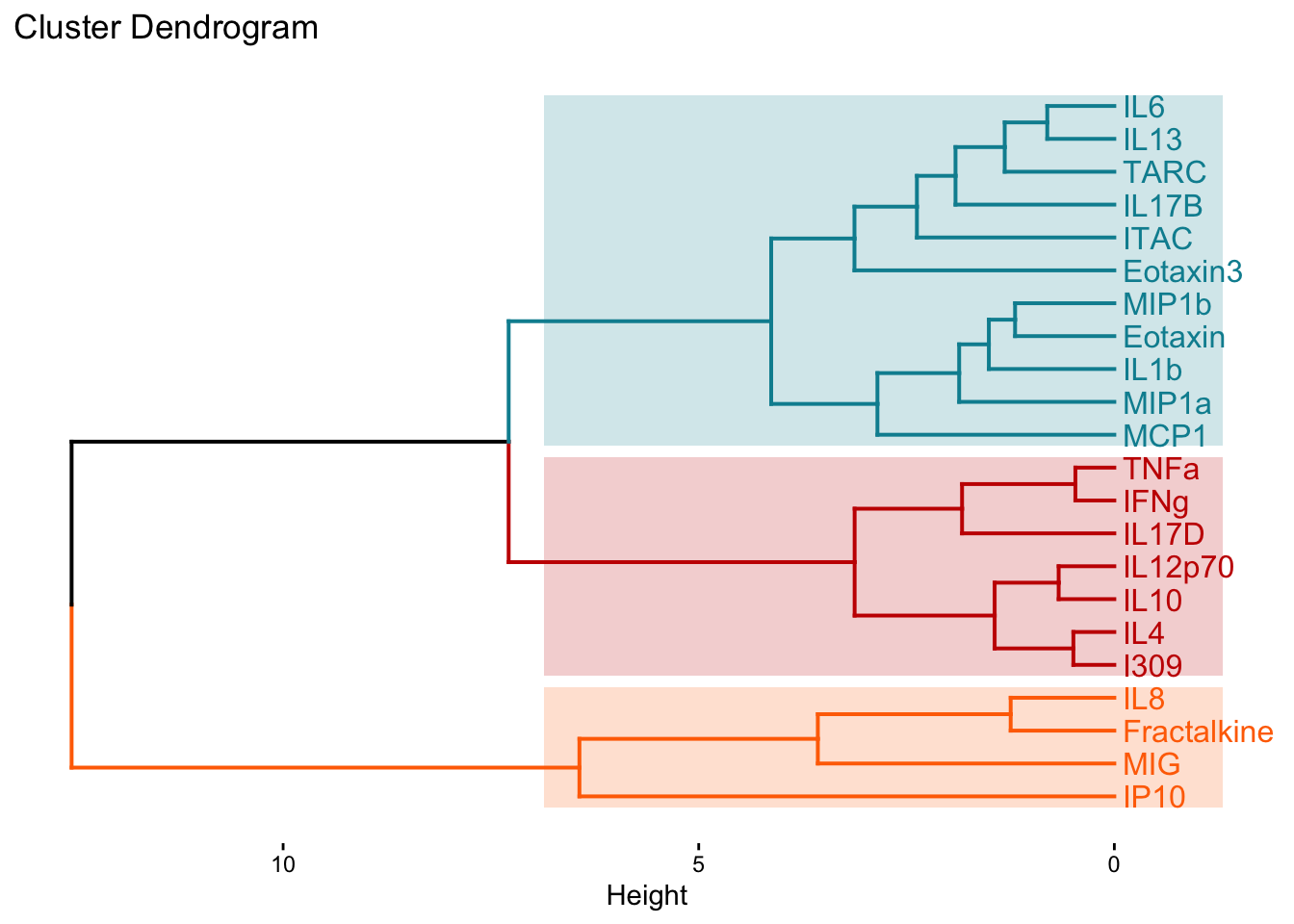
fviz_dend(cytokines_hc, k = 3, # Specifying k
cex = 0.85, # Label size
palette = "futurama", # Color palette see ?ggpubr::ggpar
rect = TRUE, rect_fill = TRUE, # Add rectangle around groups
horiz = TRUE, # Changes the orientation of the dendogram
rect_border = "futurama", # Rectangle color
labels_track_height = 0.8 # Changes the room for labels
)
We can also extract those cluster assignments using the cutree() function from the stats package.
hc_assignments_df <- data.frame(cutree(cytokines_hc, k = 3)) %>%
rownames_to_column("Cytokine") %>%
rename(`Hierarchical Cluster` = cutree.cytokines_hc..k...3.) %>%
# Ordering the dataframe for easier comparison
arrange(`Hierarchical Cluster`)
# Combining the dataframes to compare the cluster assignments from each approach
comp <- full_join(cluster_kmeans_df, hc_assignments_df, by = "Cytokine")
comp## Cytokine K-Means Cluster Hierarchical Cluster
## 1 Fractalkine 1 2
## 2 IL8 1 2
## 3 IP10 1 2
## 4 MIG 1 2
## 5 Eotaxin 2 1
## 6 Eotaxin3 2 1
## 7 IL13 2 1
## 8 IL17B 2 1
## 9 IL1b 2 1
## 10 IL6 2 1
## 11 ITAC 2 1
## 12 MCP1 2 1
## 13 MIP1a 2 1
## 14 MIP1b 2 1
## 15 TARC 2 1
## 16 I309 3 3
## 17 IFNg 3 3
## 18 IL10 3 3
## 19 IL12p70 3 3
## 20 IL17D 3 3
## 21 IL4 3 3
## 22 TNFa 3 3For additional resources on running hierarchical clustering in R, see Visualizing Clustering Dendrogram in R and Hiearchical Clustering on Principal Components.
Answer to Environmental Health Question 4
With this, we can answer Environmental Health Question #4: How do the hierarchical cluster assignments compare to the k-means cluster assignments?
Answer: Though this may not always be the case, in this instance, we see that k-means and hierarchical clustering with k=3 clusters yield the same groupings despite the clusters being presented in a different order.
Clustering Plot
One additional way to visualize clustering is to plot the first two principal components on the axes and color the data points based on their corresponding cluster. This visualization can be used for both k-means and hierarchical clustering using the fviz_cluster() function. This figure is essentially a PCA plot with shapes drawn around each cluster to make them distinct from each other.
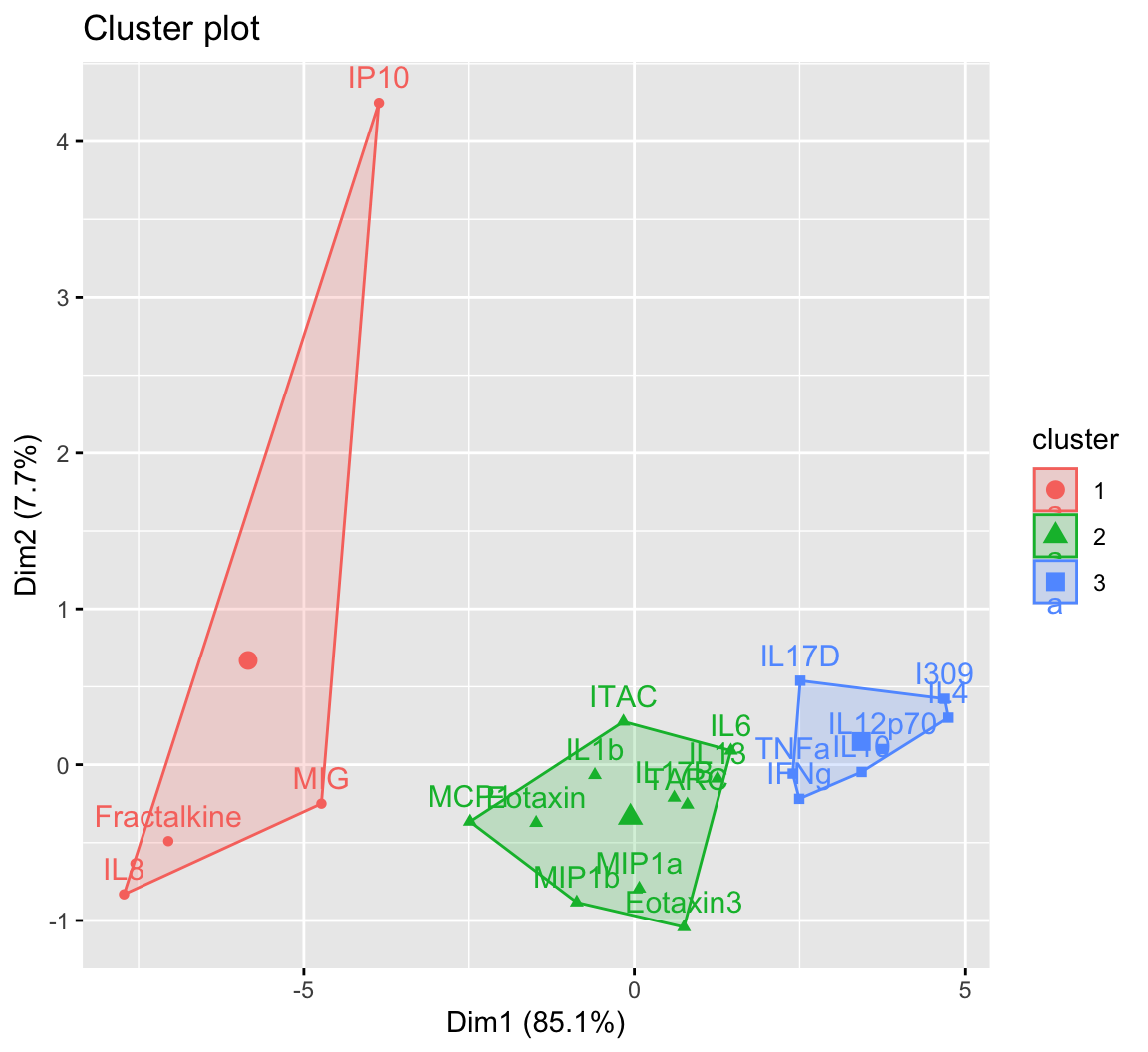
Rather than using the fviz_cluster() function as shown in the figure above, we’ll extract the data to recreate the sample figure using ggplot(). For the manuscript this was necessary, since it was important to facet the plots for each compartment (i.e., NLF, NELF, sputum, and serum). For a single plot, this data extraction isn’t required, and the figure above can be further customized within the fviz_cluster() function. However, we’ll go through the steps of obtaining the indices to recreate the same polygons in ggplot() directly.
K-means actually uses principal component analysis (PCA) to reduce a dataset’s dimensionality prior to obtaining the cluster assignments and plotting those clusters. Therefore, to obtain the coordinates of each cytokine within their respective clusters, PCA will need to be run first.
# First running PCA
pca_cytokine <- prcomp(wider_baseline_df, scale = TRUE, center = TRUE)
# Only need PC1 and PC2 for plotting, so selecting the first two columns
baseline_scores_df <- data.frame(scores(pca_cytokine)[,1:2])
baseline_scores_df$Cluster <- cluster_kmeans_3$cluster
baseline_scores_df$Protein <- rownames(baseline_scores_df)
# Changing cluster to a character for plotting
baseline_scores_df$Cluster = as.character(baseline_scores_df$Cluster)
head(baseline_scores_df)## PC1 PC2 Cluster Protein
## Eotaxin -1.4837936 -0.37325290 2 Eotaxin
## Eotaxin3 0.7505718 -1.04251406 2 Eotaxin3
## Fractalkine -7.0500961 -0.49034208 1 Fractalkine
## I309 4.6869896 0.42263944 3 I309
## IFNg 2.4935464 -0.21910385 3 IFNg
## IL10 3.4361668 -0.04689913 3 IL10Within each cluster, the chull() function is used to compute the indices of the points on the convex hull. These are needed for ggplot() to create the polygon shapes of each cluster.
# hull values for cluster 1
cluster_1 <- baseline_scores_df[baseline_scores_df$Cluster == 1, ][chull(baseline_scores_df %>%
filter(Cluster == 1)),]
# hull values for cluster 2
cluster_2 <- baseline_scores_df[baseline_scores_df$Cluster == 2, ][chull(baseline_scores_df %>%
filter(Cluster == 2)),]
# hull values for cluster 3
cluster_3 <- baseline_scores_df[baseline_scores_df$Cluster == 3, ][chull(baseline_scores_df %>%
filter(Cluster == 3)),]
all_hulls_baseline <- rbind(cluster_1, cluster_2, cluster_3)
# Changing cluster to a character for plotting
all_hulls_baseline$Cluster = as.character(all_hulls_baseline$Cluster)
head(all_hulls_baseline)## PC1 PC2 Cluster Protein
## MIG -4.7353654 -0.2498662 1 MIG
## IL8 -7.7200078 -0.8317172 1 IL8
## IP10 -3.8660925 4.2481655 1 IP10
## Eotaxin3 0.7505718 -1.0425141 2 Eotaxin3
## MIP1b -0.8699488 -0.8834532 2 MIP1b
## MCP1 -2.4837364 -0.3652235 2 MCP1Now plotting the clusters using ggplot().
ggplot() +
geom_point(data = baseline_scores_df, aes(x = PC1, y = PC2, color = Cluster, shape = Cluster), size = 4) +
# Adding cytokine names
geom_text_repel(data = baseline_scores_df, aes(x = PC1, y = PC2, color = Cluster, label = Protein),
show.legend = FALSE, size = 4.5) +
# Creating polygon shapes of the clusters
geom_polygon(data = all_hulls_baseline, aes(x = PC1, y = PC2, group = as.factor(Cluster), fill = Cluster,
color = Cluster), alpha = 0.25, show.legend = FALSE) +
theme_light() +
theme(axis.text.x = element_text(vjust = 0.5), #rotating x labels/ moving x labels slightly to the left
axis.line = element_line(colour="black"), #making x and y axes black
axis.text = element_text(size = 13), #changing size of x axis labels
axis.title = element_text(face = "bold", size = rel(1.7)), #changes axis titles
legend.title = element_text(face = 'bold', size = 17), #changes legend title
legend.text = element_text(size = 14), #changes legend text
legend.position = 'bottom', # moving the legend to the bottom
legend.background = element_rect(colour = 'black', fill = 'white', linetype = 'solid'), #changes the legend background
strip.text.x = element_text(size = 18, face = "bold"), #changes size of facet x axis
strip.text.y = element_text(size = 18, face = "bold")) + #changes size of facet y axis
xlab('Dimension 1 (85.1%)') + ylab('Dimension 2 (7.7%)') + #changing axis labels
# Using colors from the startrek palette from ggsci
scale_color_startrek(name = 'Cluster') +
scale_fill_startrek(name = 'Cluster') 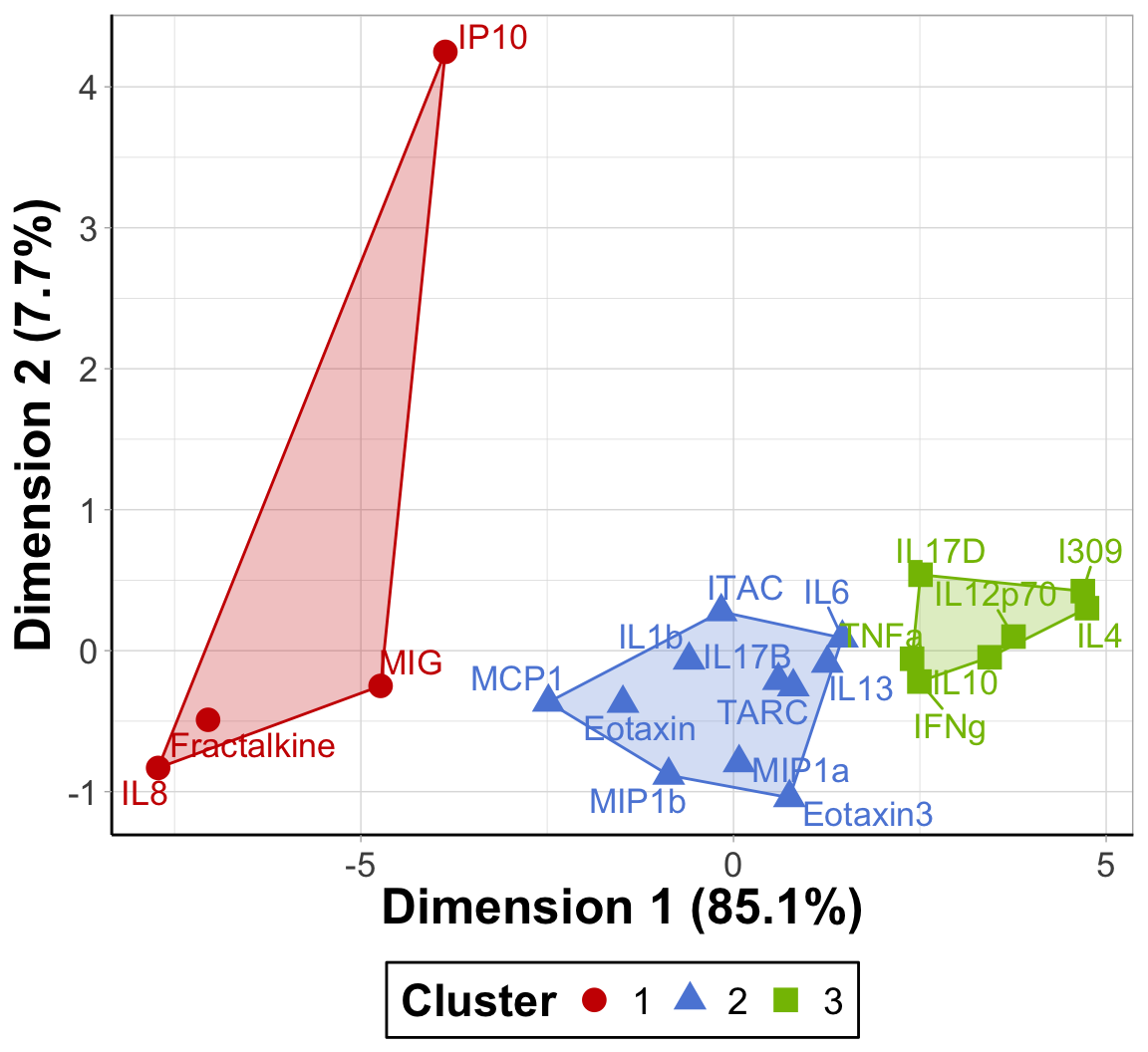
An appropriate title for this figure could be:
“Figure X. K-means clusters of cytokines at baseline. Cytokines samples are derived from nasal epithelium (NELF) samples in 14 non-smoking subjects. Cytokine concentration values were transformed using a data reduction technique known as Principal Component Analysis (PCA). The first two eigenvectors plotted on the axes were able to capture a majority of the variance across all samples from the original dataset.”
Takeaways from this clustering plot:
- PCA was able to capture almost all (~93%) of the variance from the original dataset
- The 22 cytokines were able to be clustered into 3 distinct clusters using k-means
Hierarchical Clustering Visualization
We can also build a heatmap using the pheatmap() function that has the capability to display hierarchical clustering dendrograms. To do so, we’ll need to go back and use the wider_baseline_df dataframe.
pheatmap(wider_baseline_df,
cluster_cols = FALSE, # hierarchical clustering of cytokines
scale = "column", # scaling the data to make differences across cytokines more apparent
cutree_row = 3, # adds a space between the 3 largest clusters
display_numbers = TRUE, number_color = "black", fontsize = 12, # adding average concentration values
angle_col = 45, fontsize_col = 12, fontsize_row = 12, # adjusting size/ orientation of axes labels
cellheight = 17, cellwidth = 30 # setting height and width for cells
)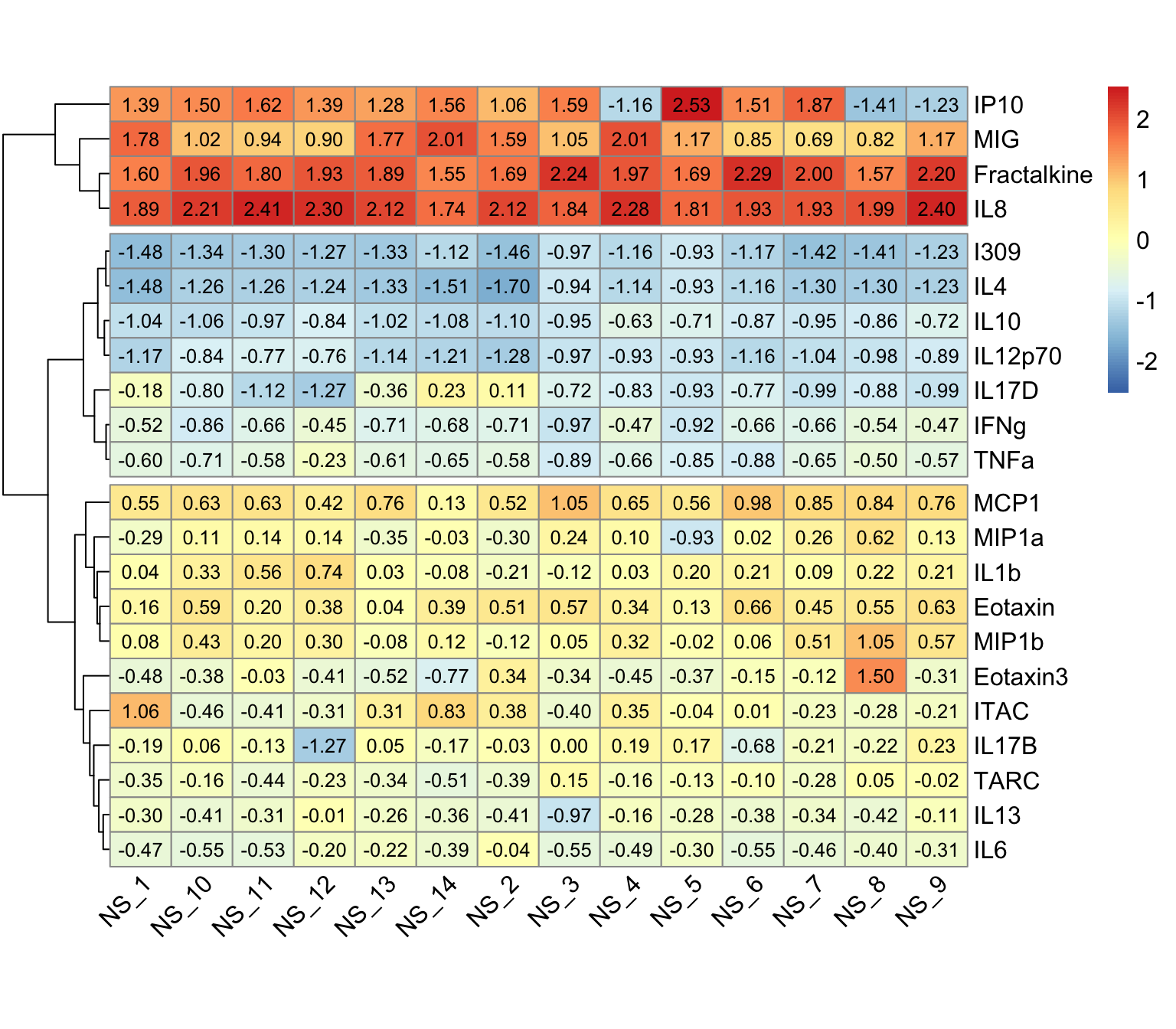
An appropriate title for this figure could be:
“Figure X. Hierarchical clustering of cytokines at baseline. Cytokines samples are derived from nasal epithelium (NELF) samples in 14 non-smoking subjects. The heatmap visualizes psuedo log2 cytokine concentrations that were scaled within each subject.”
It may be helpful to add axes titles like “Subject ID” for the x axis, “Cytokine” for the y axis, and “Scaled pslog2 Concentration” for the legend after exporting from R. The pheatmap() function does not have the functionality to add those titles.
Nevertheless, let’s identify some key takeaways from this heatmap:
- The 22 cytokines were able to be clustered into 3 distinct clusters using hierarchical clustering
- These clusters are based on cytokine concentration levels with the first cluster having the highest expression, the second cluster having the lowest expression, and the last cluster having average expression
Variable Contributions
To answer our final environmental health question: Which cytokines have the greatest contributions to the first two eigenvectors, we’ll use the fviz_contrib() function that plots the percentage of each variable’s contribution to the principal component(s). It also displays a red dashed line, and variables that fall above are considered to have significant contributions to those principal components. For a refresher on PCA and variable contributions, see the previous module, TAME 2.0 Module 5.4 Unsupervised Machine Learning.
# kmeans contributions
fviz_contrib(pca_cytokine,
choice = "ind", addlabels = TRUE,
axes = 1:2) # specifies to show contribution percentages for first 2 PCs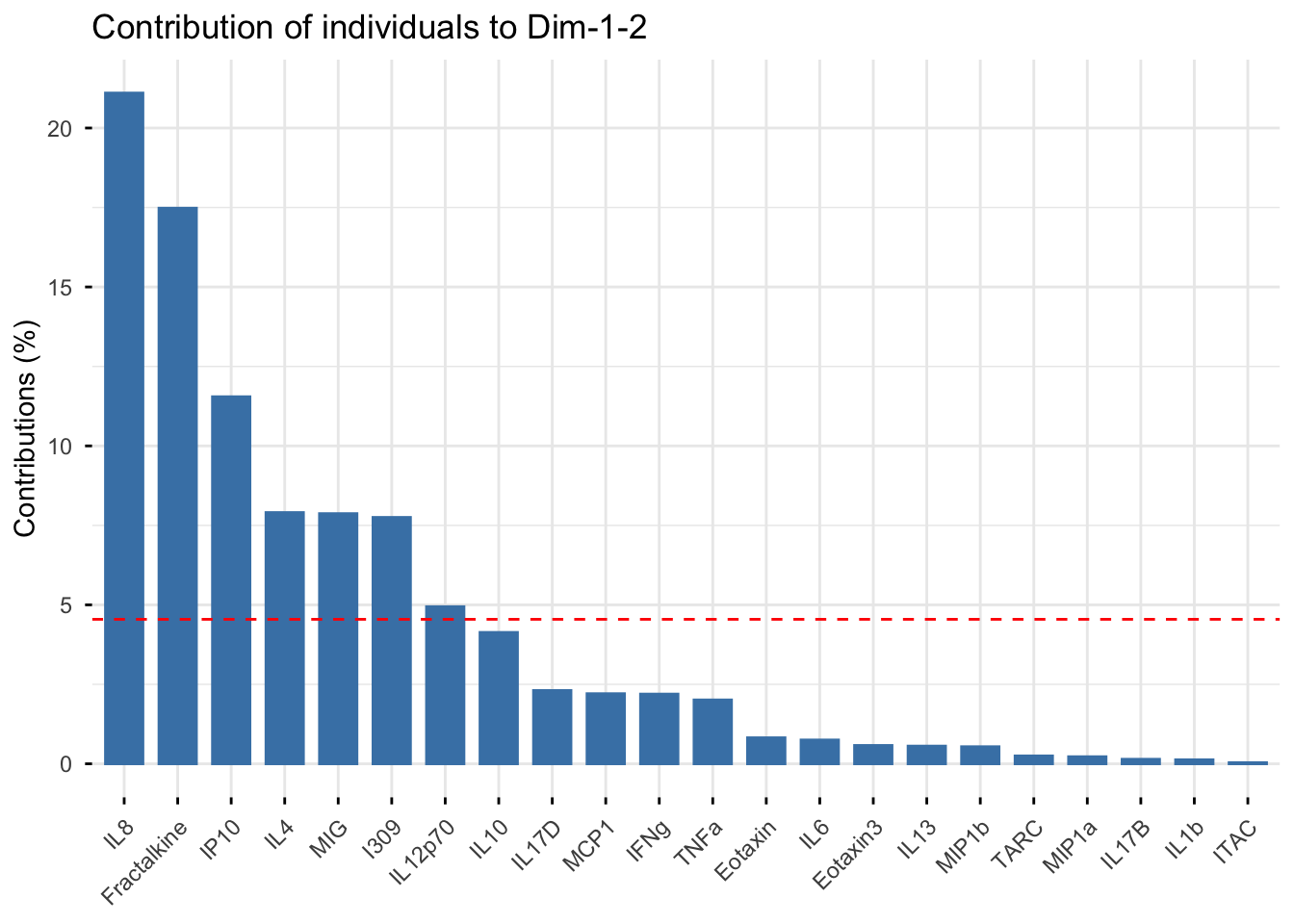
An appropriate title for this figure could be:
“Figure X. Cytokine contributions to principal components. The bar chart displays each cytokine’s contribution to the first two eigenvectors in descending order from left to right. The red dashed line represents the expected contribution of each cytokine if all inputs were uniform, therefore the seven cytokines that fall above this reference line are considered to have significant contributions to the first two principal components.”
Answer to Environmental Health Question 5
With this, we can answer Environmental Health Question #5: Which cytokines have the greatest contributions to the first two eigenvectors?
Answer: The cytokines that have significant contributions to the first two principal components include IL-8, Fractalkine, IP-10, IL-4, MIG, I309, and IL-12p70.
Concluding Remarks
In this module, we explored scenarios where clustering would be appropriate but lack contextual details informing the number of clusters that should be considered, thus resulting in the need to derive such a number. In addition, methodology for k-means and hierarchical clustering was presented, along with corresponding visualizations. Lastly, variable contributions to the eigenvectors were introduced as a means to determine the most influential variables on the principal components’ composition.
Additional Resources
Using the same dataset, answer the questions below.
- Determine the optimal number of k-means clusters of cytokines derived from the nasal epithelieum lining fluid of e-cigarette users.
- How do those clusters compare to the ones that were derived at baseline (in non-smokers)?
- Which cytokines have the greatest contributions to the first two eigenvectors?