3.1 Data Visualizations
This training module was developed by Alexis Payton, Kyle Roell, Lauren E. Koval, Elise Hickman, and Julia E. Rager.
All input files (script, data, and figures) can be downloaded from the UNC-SRP TAME2 GitHub website.
Introduction to Data Visualizations
Selecting an approach to visualize data is an important consideration when presenting scientific research, given that figures have the capability to summarize large amounts of data efficiently and effectively. (At least that’s the goal!) This module will focus on basic data visualizations that we view to be most commonly used, both in and outside of the field of environmental health research, many of which you have likely seen before. This module is not meant to be an exhaustive representation of all figure types, rather it serves as an introduction to some types of figures and how to approach choosing the one that most optimally displays your data and primary findings. When selecting a data visualization approach, here are some helpful questions you should first ask yourself:
- What message am I trying to convey with this figure?
- How does this figure highlight major findings from the paper?
- Who is the audience?
- What type of data am I working with?
A Guide To Getting Data Visualization Right is a great resource for determining which figure is best suited for various types of data. More complex methodology-specific charts are presented in succeeding TAME modules. These include visualizations for:
- Two Group Comparisons (e.g.,boxplots and logistic regression) in Module 3.4 Introduction to Statistical Tests and Module 4.4 Two Group Comparisons and Visualizations
- Multi-Group Comparisons (e.g.,boxplots) in Module 3.4 Introduction to Statistical Tests and Module 4.5 Multi-Group Comparisons and Visualizations
- Supervised Machine Learning (e.g.,decision boundary plots, variable importance plots) in Module 5.3 Supervised ML Model Interpretation
- Unsupervised Machine Learning
- Principal Component Analysis (PCA) plots and heatmaps in Module 5.4 Unsupervised Machine Learning Part 1: K-Means Clustering & PCA
- Dendrograms, clustering visualizations, heatmaps, and variable contribution plots in Module 5.5 Unsupervised Machine Learning Part 2: Additional Clustering Applications
- -Omics Expression (e.g.,MA plots and volcano plots) in Module 6.2 -Omics and Systems Biology: Transcriptomic Applications
- Mixtures Methods
- Forest Plots in Module 6.3 Mixtures I: Overview and Quantile G-Computation Application
- Trace Plots in Module 6.4 Mixtures II: BKMR Application
- Sufficient Similarity (e.g.,heatmaps, clustering) in Module 6.5 Mixtures III: Sufficient Similarity
- Toxicokinetic Modeling (e.g.,line graph, dose response) in Module 6.6 Toxicokinetic Modeling
Introduction to Training Module
Visualizing data is an important step in any data analysis, including those carried out in environmental health research. Often, visualizations allow scientists to better understand trends and patterns within a particular dataset under evaluation. Even after statistical analysis of a dataset, it is important to then communicate these findings to a wide variety of target audiences. Visualizations are a vital part of communicating complex data and results to target audiences.
In this module, we highlight some figures that can be used to visualize larger, more high-dimensional datasets using figures that are more simple (but still relevant!) than methods presented later on in TAME. This training module specifically reviews the formatting of data in preparation of generating visualizations, scaling datasets, and then guides users through the generation of the following example data visualizations:
- Density plots
- Boxplots
- Correlation plots
- Heatmaps
These visualization approaches are demonstrated using a large environmental chemistry dataset. This example dataset was generated through chemical speciation analysis of smoke samples collected during lab-based simulations of wildfire events. Specifically, different biomass materials (eucalyptus, peat, pine, pine needles, and red oak) were burned under two combustion conditions of flaming and smoldering, resulting in the generation of 12 different smoke samples. These data have been previously published in the following environmental health research studies, with data made publicly available:
- Rager JE, Clark J, Eaves LA, Avula V, Niehoff NM, Kim YH, Jaspers I, Gilmour MI. Mixtures modeling identifies chemical inducers versus repressors of toxicity associated with wildfire smoke. Sci Total Environ. 2021 Jun 25;775:145759. doi: 10.1016/j.scitotenv.2021.145759. Epub 2021 Feb 10. PMID: 33611182.
- Kim YH, Warren SH, Krantz QT, King C, Jaskot R, Preston WT, George BJ, Hays MD, Landis MS, Higuchi M, DeMarini DM, Gilmour MI. Mutagenicity and Lung Toxicity of Smoldering vs. Flaming Emissions from Various Biomass Fuels: Implications for Health Effects from Wildland Fires. Environ Health Perspect. 2018 Jan 24;126(1):017011. doi: 10.1289/EHP2200. PMID: 29373863.
GGplot2
ggplot2 is a powerful package used to create graphics in R. It was designed based on the philosophy that every figure can be built using a dataset, a coordinate system, and a geom that specifies the type of plot. As a result, it is fairly straightforward to create highly customizable figures and is typically preferred over using base R to generate graphics. We’ll generate all of the figures in this module using ggplot2.
For additional resources on ggplot2 see ggplot2 Posit Documentation and Data Visualization with ggplot2.
Script Preparations
Installing required R packages
If you already have these packages installed, you can skip this step, or you can run the below code which checks installation status for you
Importing example dataset
Then let’s read in our example dataset. As mentioned in the introduction, this example dataset represents chemical measurements across 12 different biomass burn scenarios representing potential wildfire events. Let’s upload and view these data:
# Load the data
smoke_data <- read.csv("Chapter_3/3_1_Data_Visualization/Module3_1_InputData.csv")
# View the top of the dataset
head(smoke_data) ## Chemical.Category Chemical CASRN Eucalyptus_Smoldering
## 1 n-Alkanes 2-Methylnonadecane 1560-86-7 0.06
## 2 n-Alkanes 3-Methylnonadecane 6418-45-7 0.04
## 3 n-Alkanes Docosane 629-97-0 0.21
## 4 n-Alkanes Dodecylcyclohexane 1795-17-1 0.04
## 5 n-Alkanes Eicosane 112-95-8 0.11
## 6 n-Alkanes Heneicosane 629-94-7 0.13
## Eucalyptus_Flaming Peat_Smoldering Peat_Flaming Pine_Smoldering Pine_Flaming
## 1 0.06 1.36 0.06 0.06 0.06
## 2 0.04 1.13 0.90 0.47 0.04
## 3 0.25 9.46 0.57 0.16 0.48
## 4 0.04 0.25 0.04 0.04 0.04
## 5 0.25 7.55 0.54 0.17 0.29
## 6 0.28 6.77 0.34 0.13 0.42
## Pine_Needles_Smoldering Pine_Needles_Flaming Red_Oak_Smoldering
## 1 0.06 0.06 0.06
## 2 0.04 0.72 0.04
## 3 0.32 0.18 0.16
## 4 0.12 0.04 0.04
## 5 0.28 0.16 0.15
## 6 0.30 0.13 0.13
## Red_Oak_Flaming Units
## 1 0.13 ng_per_uL
## 2 0.77 ng_per_uL
## 3 0.36 ng_per_uL
## 4 0.04 ng_per_uL
## 5 0.38 ng_per_uL
## 6 0.69 ng_per_uLTraining Module’s Environmental Health Questions
This training module was specifically developed to answer the following environmental health questions:
- How do the distributions of the chemical concentration data differ based on each biomass burn scenario?
- Are there correlations between biomass burn conditions based on the chemical concentration data?
- Under which biomass burn conditions are concentrations of certain chemical categories the highest?
We can create a density plot to answer the first question. Similar to a histogram, density plots are an effective way to show overall distributions of data and can be useful to compare across various test conditions or other stratifications of the data.
In this example of a density plot, we’ll visualize the distributions of chemical concentration data on the x axis. A density plot automatically displays where values are concentrated on the y axis. Additionally, we’ll want to have multiple density plots within the same figure for each biomass burn condition.
Before the data can be visualized, it needs to be converted from a wide to long format. This is because we need to have variable or column names entitled Chemical_Concentration and Biomass_Burn_Condition that can be placed into ggplot(). For review on converting between long and wide formats and using other tidyverse tools, see TAME 2.0 Module 2.3 Data Manipulation & Reshaping.
longer_smoke_data = pivot_longer(smoke_data, cols = 4:13, names_to = "Biomass_Burn_Condition",
values_to = "Chemical_Concentration")
head(longer_smoke_data)## # A tibble: 6 × 6
## Chemical.Category Chemical CASRN Units Biomass_Burn_Condition
## <chr> <chr> <chr> <chr> <chr>
## 1 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Smoldering
## 2 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Flaming
## 3 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Smoldering
## 4 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Flaming
## 5 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Smoldering
## 6 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Flaming
## # ℹ 1 more variable: Chemical_Concentration <dbl>Scaling dataframes for downstream data visualizations
A data preparation method that is commonly used to convert values into those that can be used to better illustrate overall data trends is data scaling. Scaling can be achieved through data transformations or normalization procedures, depending on the specific dataset and goal of analysis/visualization. Scaling is often carried out using data vectors or columns of a dataframe.
For this example, we will normalize the chemical concentration dataset using a basic scaling and centering procedure using the base R function, scale(). This algorithm results in the normalization of a dataset using the mean value and standard deviation. This scaling step will convert chemical concentration values in our dataset into normalized values across samples, such that each chemical’s concentration distributions are more easily comparable between the different biomass burn conditions.
For more information on the scale() function, see its associated RDocumentation and helpful tutorial on Implementing the scale() function in R.
scaled_longer_smoke_data = longer_smoke_data %>%
# scaling within each chemical
group_by(Chemical) %>%
mutate(Scaled_Chemical_Concentration = scale(Chemical_Concentration)) %>%
ungroup()
head(scaled_longer_smoke_data) # see the new scaled values now in the last column (column 7)## # A tibble: 6 × 7
## Chemical.Category Chemical CASRN Units Biomass_Burn_Condition
## <chr> <chr> <chr> <chr> <chr>
## 1 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Smoldering
## 2 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Flaming
## 3 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Smoldering
## 4 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Flaming
## 5 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Smoldering
## 6 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Flaming
## # ℹ 2 more variables: Chemical_Concentration <dbl>,
## # Scaled_Chemical_Concentration <dbl[,1]>We can see that in the Scaled_Chemical_Concentration column, each chemical is scaled based on a normal distribution centered around 0, with values now less than or greater than zero.
Now that we have our dataset formatted, let’s plot it.
Density Plot Visualization
The following code can be used to generate a density plot:
ggplot(scaled_longer_smoke_data, aes(x = Scaled_Chemical_Concentration, color = Biomass_Burn_Condition)) +
geom_density()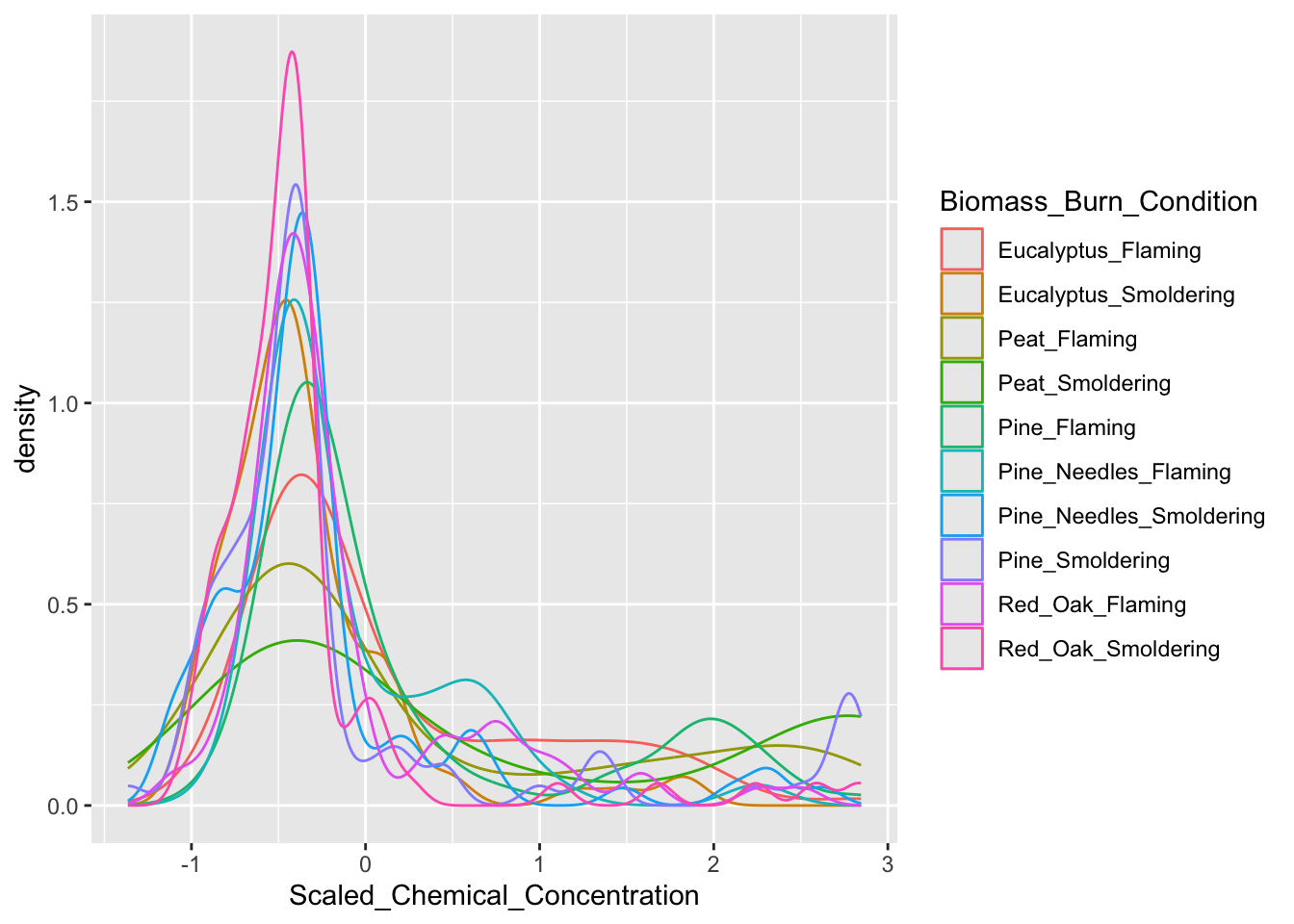
Answer to Environmental Health Question 1, Method I
With this method, we can answer Environmental Health Question #1: How do the distributions of the chemical concentration data differ based on each biomass burn scenario?
Answer: In general, there are a high number of chemicals that were measured at relatively lower abundances across all smoke samples (hence, the peak in occurrence density occurring towards the left, before 0). The three conditions of smoldering peat, flaming peat, and flaming pine contained the most chemicals at the highest relative concentrations (hence, these lines are the top three lines towards the right).
Boxplot Visualization
A boxplot can also be used to answer our first environmental health question: How do the distributions of the chemical concentration data differ based on each biomass burn scenario?. A boxplot also displays a data’s distribution, but it incorporates a visualization of a five number summary (i.e., minimum, first quartile, median, third quartile, and maximum). Any outliers are displayed as dots.
For this example, let’s have Scaled_Chemical_Concentration on the x axis and Biomass_Burn_Condition on the y axis. The scaled_longer_smoke_data dataframe is the format we need, so we’ll use that for plotting.
ggplot(scaled_longer_smoke_data, aes(x = Scaled_Chemical_Concentration, y = Biomass_Burn_Condition,
color = Biomass_Burn_Condition)) +
geom_boxplot()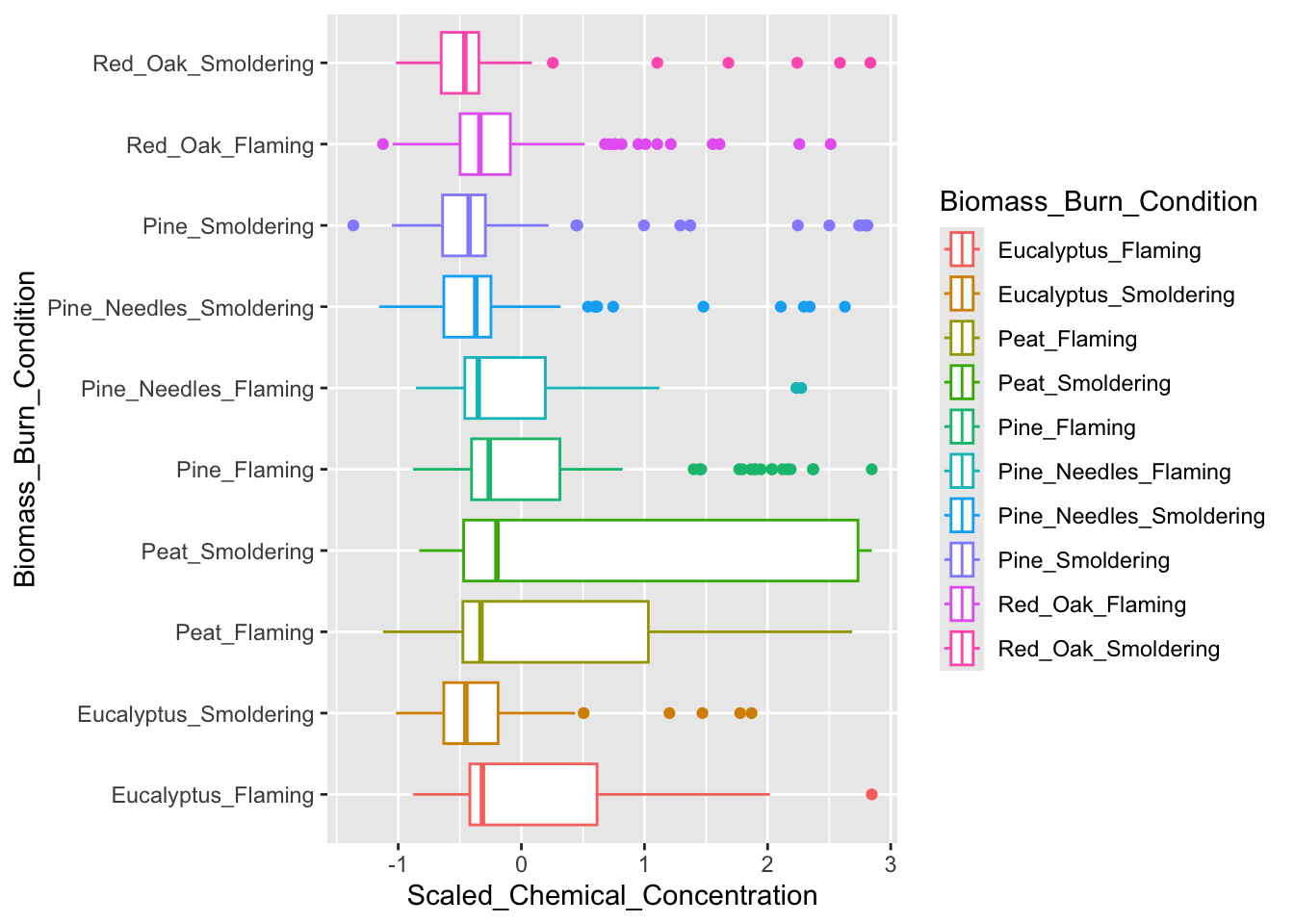
Answer to Environmental Health Question 1, Method II
With this alternative method, we can answer, in a different way, Environmental Health Question #1: How do the distributions of the chemical concentration data differ based on each biomass burn scenario?
Answer, Method II: The median chemical concentration is fairly low (less than 0) for all biomass burn conditions. Overall, there isn’t much variation in chemical concentrations with the exception of smoldering peat, flaming peat, and flaming eucalyptus.
Correlation Visualizations
Let’s turn our attention to the second environmental health question: Are there correlations between biomass burn conditions based on the chemical concentration data? We’ll use two different correlation visualizations to answer this question using the GGally package.
GGally is a package that serves as an extension of ggplot2, the baseline R plotting system based on the grammar of graphics. GGally is very useful for creating plots that compare groups or features within a dataset, among many other utilities. Here we will demonstrate the ggpairs() function within GGally using the scaled chemistry dataset. This function will produce an image that shows correlation values between biomass burn sample pairs and also illustrates the overall distributions of values in the samples. For more information on GGally, see its associated RDocumentation and example helpful tutorial.
GGally requires a wide dataframe with ids (i.e.,Chemical) as the rows and the variables that will be compared to each other (i.e.,Biomass_Burn_Condition) as the columns. Let’s create that dataframe.
# first selecting the chemical, biomass burn condition, and
# the scaled chemical concentration columns
wide_scaled_data = scaled_longer_smoke_data %>%
pivot_wider(id_cols = Chemical, names_from = "Biomass_Burn_Condition",
values_from = "Scaled_Chemical_Concentration") %>%
# converting the chemical names to row names
column_to_rownames(var = "Chemical")
head(wide_scaled_data)## Eucalyptus_Smoldering Eucalyptus_Flaming Peat_Smoldering
## 2-Methylnonadecane -0.3347765 -0.3347765 2.841935
## 3-Methylnonadecane -0.8794448 -0.8794448 1.649829
## Docosane -0.3465132 -0.3327216 2.842787
## Dodecylcyclohexane -0.4240624 -0.4240624 2.646734
## Eicosane -0.3802202 -0.3195928 2.841691
## Heneicosane -0.3895328 -0.3166775 2.835527
## Peat_Flaming Pine_Smoldering Pine_Flaming
## 2-Methylnonadecane -0.3347765 -0.3347765 -0.3347765
## 3-Methylnonadecane 1.1161291 0.1183422 -0.8794448
## Docosane -0.2223890 -0.3637526 -0.2534201
## Dodecylcyclohexane -0.4240624 -0.4240624 -0.4240624
## Eicosane -0.1940076 -0.3542370 -0.3022707
## Heneicosane -0.2875354 -0.3895328 -0.2486793
## Pine_Needles_Smoldering Pine_Needles_Flaming
## 2-Methylnonadecane -0.3347765 -0.3347765
## 3-Methylnonadecane -0.8794448 0.6984509
## Docosane -0.3085863 -0.3568568
## Dodecylcyclohexane 0.7457649 -0.4240624
## Eicosane -0.3066012 -0.3585675
## Heneicosane -0.3069635 -0.3895328
## Red_Oak_Smoldering Red_Oak_Flaming
## 2-Methylnonadecane -0.3347765 -0.1637228
## 3-Methylnonadecane -0.8794448 0.8144726
## Docosane -0.3637526 -0.2947948
## Dodecylcyclohexane -0.4240624 -0.4240624
## Eicosane -0.3628981 -0.2632960
## Heneicosane -0.3895328 -0.1175398By default, ggpairs() displays Pearson’s correlations. To show Spearman’s correlations takes more nuance, but can be done using the code that has been commented out below.
# ggpairs with Pearson's correlations
wide_scaled_data = data.frame(as.matrix(wide_scaled_data))
ggpairs(wide_scaled_data)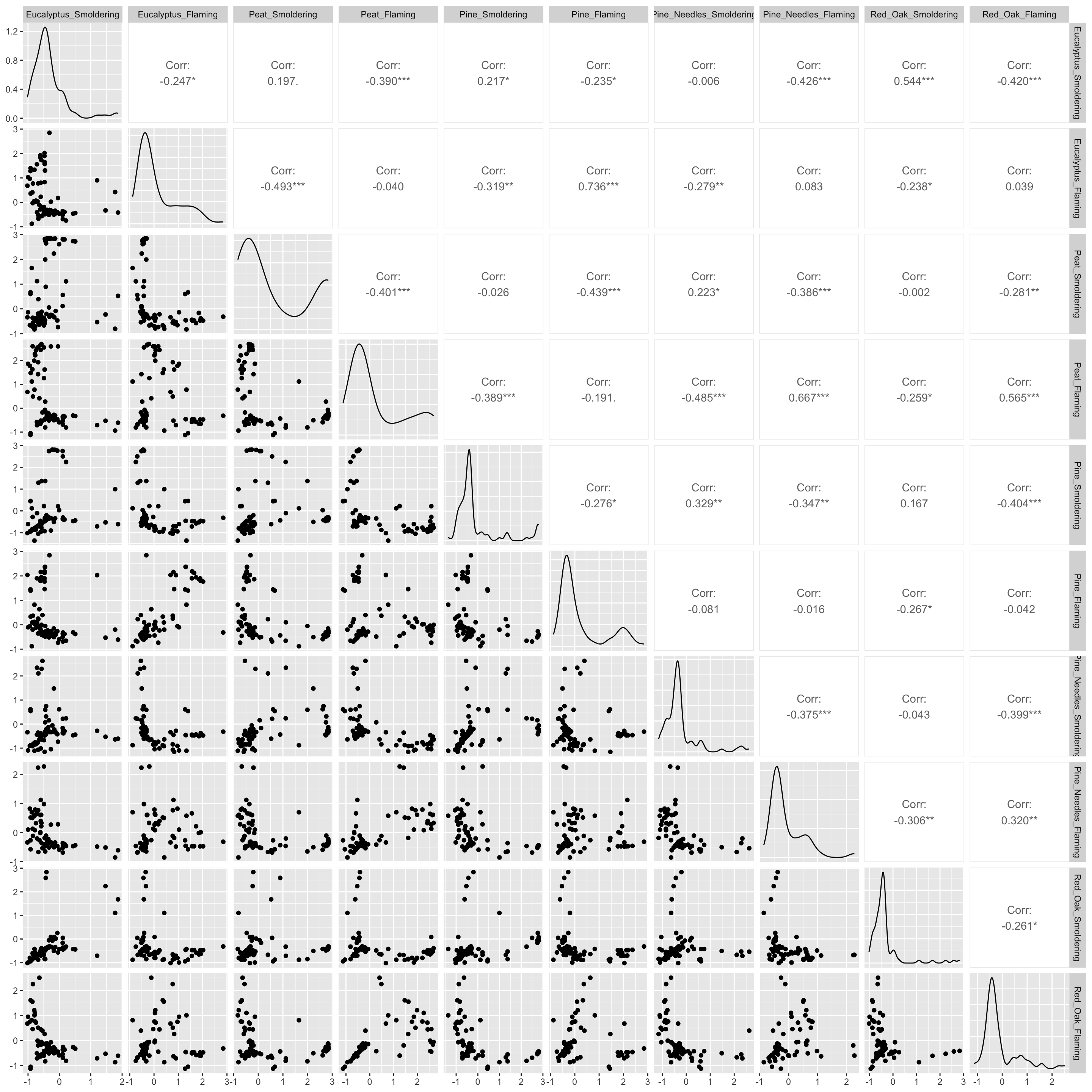
# ggpairs with Spearman's correlations
# pearson_correlations = cor(wide_scaled_data, method = "spearman")
# ggpairs(wide_scaled_data, upper = list(continuous = wrap(ggally_cor, method = "spearman")))Many of these biomass burn conditions have significant correlations denoted by the asterisks.
- ’*’: p value < 0.1
- ’**’: p value < 0.05
- ’***’: p value < 0.01
The upper right portion displays the correlation values, where a value less than 0 indicates negative correlation and a value greater than 0 signifies positive correlation. The diagonal shows the density plots for each variable. The lower left portion visualizes the values of the two variables compared using a scatterplot.
Answer to Environmental Health Question 2
With this, we can answer Environmental Health Question #2: Are there correlations between biomass burn conditions based on the chemical concentration data?
Answer: There is low correlation between many of the variables (-0.5 < correlation value < 0.5). Eucalyptus flaming and pine flaming are significantly positively correlated along with peat flaming and pine needles flaming (correlation value ~0.7 and p value < 0.001).
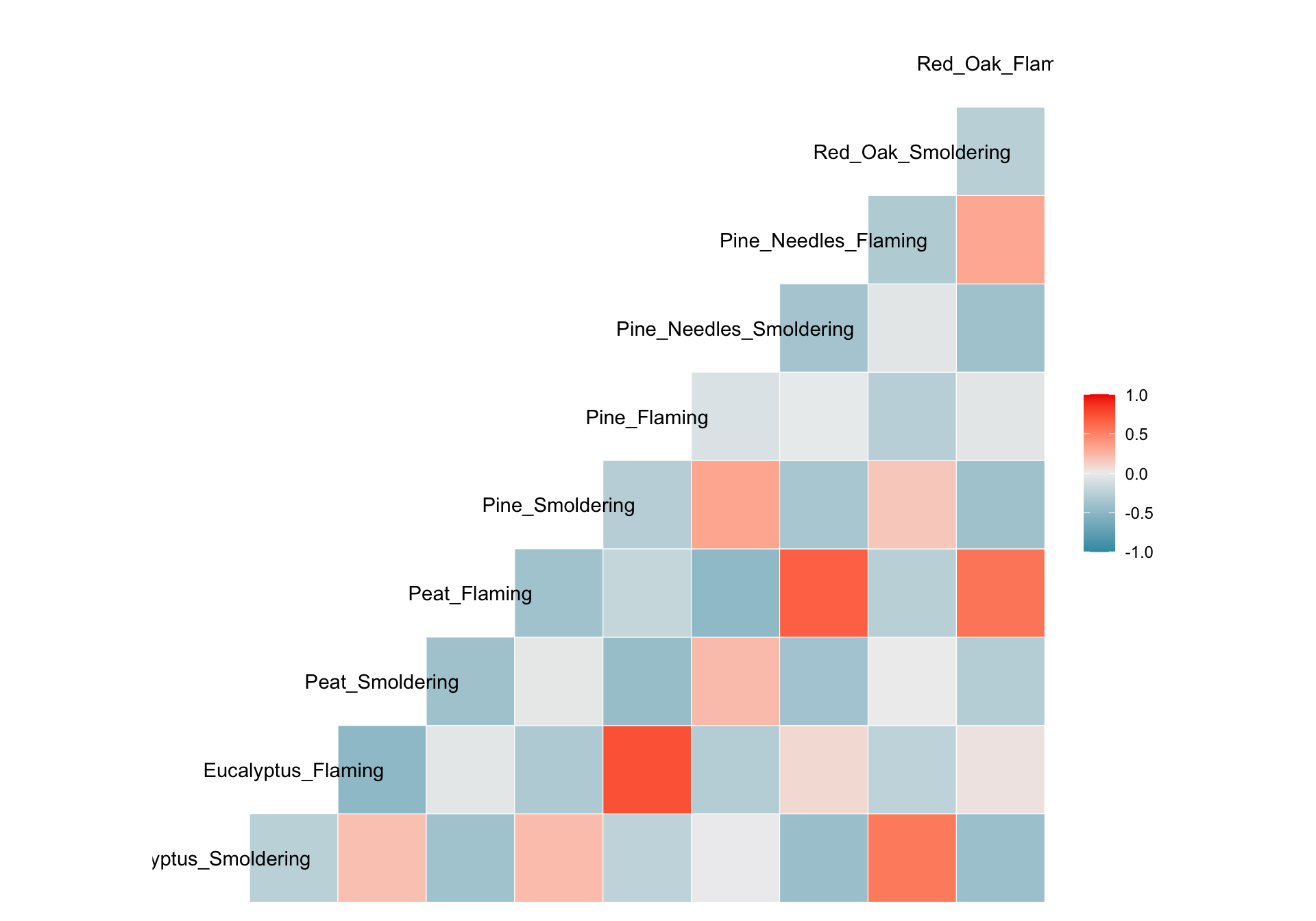
We can visualize correlations another way using the other function from GGally, ggcorr(), which visualizes each correlation as a square. Note that this function calculates Pearson’s correlations by default. However, this can be changed using the method parameter shown in the code commented out below.
We’ll visualize correlations between each of the groups using one more figure using the corrplot() function from the corrplot package.
# Need to supply corrplot with a correlation matrix, here, using the 'cor' function
corrplot(cor(wide_scaled_data))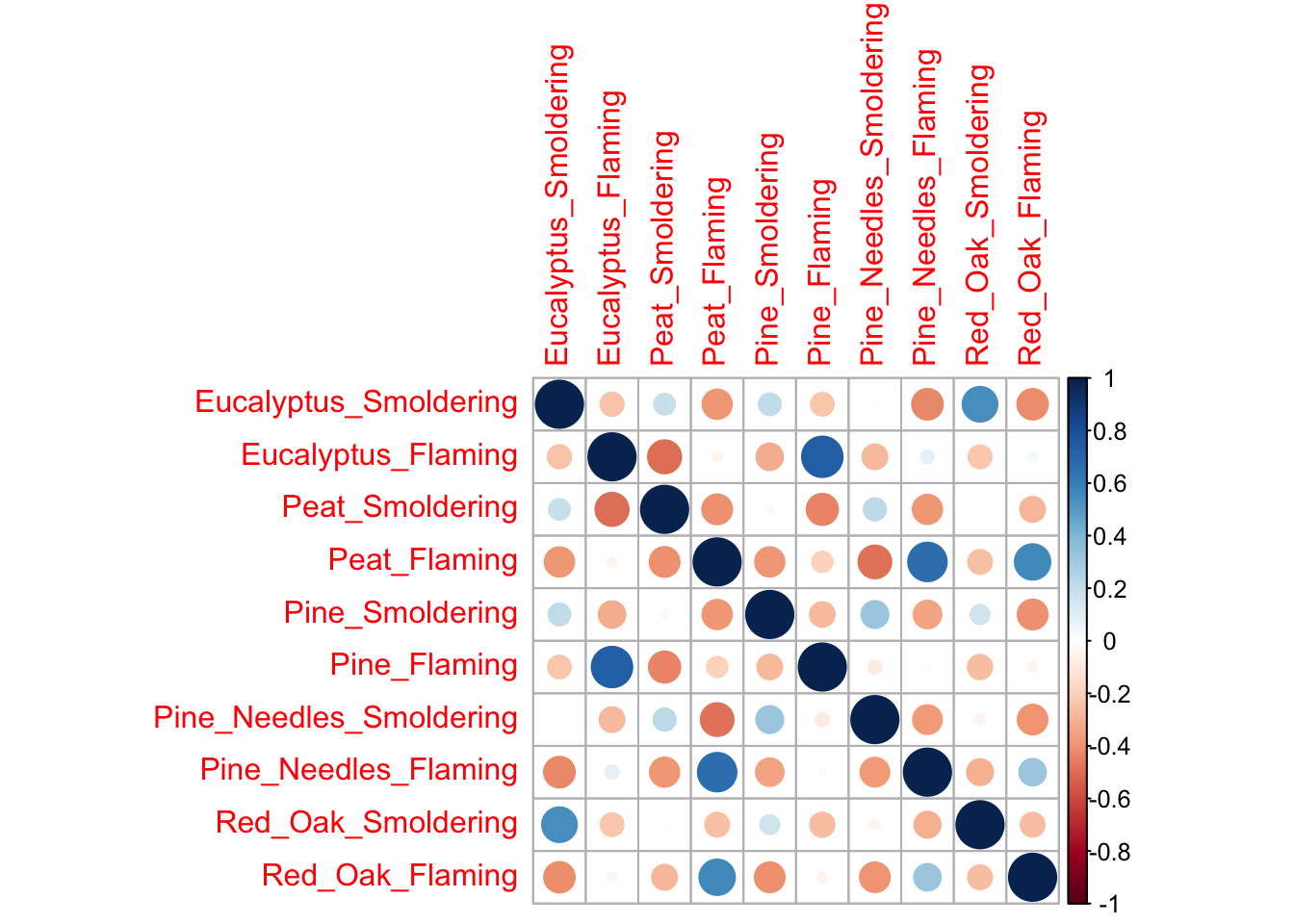
Each of these correlation figures displays the same information, but the one you choose to use is a matter of personal preference. Click on the following resources for additional information on ggpairs() and corrplot().
Heatmap Visualization
Last, we’ll turn our attention to answering the final environmental health question: Under which biomass burn conditions are concentrations of certain chemical categories the highest? This can be addressed with the help of a heatmap.
Heatmaps are a highly effective method of viewing an entire dataset at once. Heatmaps can appear similar to correlation plots, but typically illustrate other values (e.g., concentrations, expression levels, presence/absence, etc) besides correlation values. They are used to draw patterns between two variables of highest interest (that comprise the x and y axis, though additional bars can be added to display other layers of information). In this instance, we’ll use a heatmap to determine whether there are patterns apparent between chemical categories and biomass burn condition on chemical concentrations.
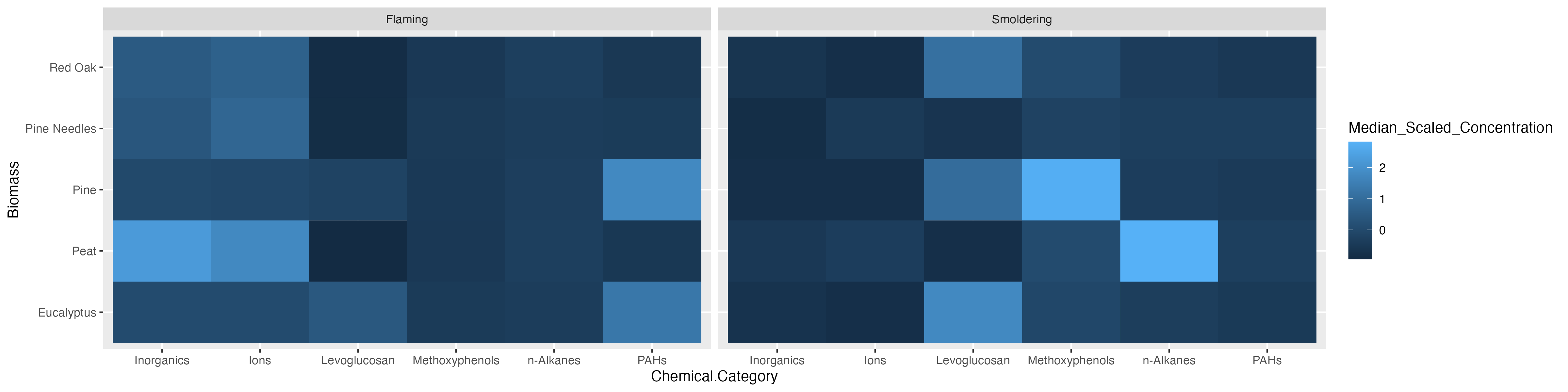
For this example, we can plot Biomass_Burn_Condition and Chemical.Category on the axes and fill in the values with Scaled_Chemical_Concentration. When generating heatmaps, scaled values are often used to better distinguish patterns between groups/samples.
In this example, we also plan to display the median scaled concentration value within the heatmap as an additional layer of helpful information to aid in interpretation. To do so, we’ll need to take the median chemical concentration for each biomass burn condition within each chemical category. However, since we want ggplot() to visualize the median scaled values with the color of the tiles this step was already necessary.
# We'll find the median value and add that data to the dataframe as an additional column
heatmap_df = scaled_longer_smoke_data %>%
group_by(Biomass_Burn_Condition, Chemical.Category) %>%
mutate(Median_Scaled_Concentration = median(Scaled_Chemical_Concentration))
head(heatmap_df)## # A tibble: 6 × 8
## # Groups: Biomass_Burn_Condition, Chemical.Category [6]
## Chemical.Category Chemical CASRN Units Biomass_Burn_Condition
## <chr> <chr> <chr> <chr> <chr>
## 1 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Smoldering
## 2 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Eucalyptus_Flaming
## 3 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Smoldering
## 4 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Peat_Flaming
## 5 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Smoldering
## 6 n-Alkanes 2-Methylnonadecane 1560-86-7 ng_per_… Pine_Flaming
## # ℹ 3 more variables: Chemical_Concentration <dbl>,
## # Scaled_Chemical_Concentration <dbl[,1]>, Median_Scaled_Concentration <dbl>Now we can plot the data and add the Median_Scaled_Concentration to the figure using geom_text(). Note that specifying the original Scaled_Chemical_Concentration in the fill parameter will NOT give you the same heatmap as specifying the median values in ggplot().
ggplot(data = heatmap_df, aes(x = Chemical.Category, y = Biomass_Burn_Condition,
fill = Median_Scaled_Concentration)) +
geom_tile() + # function used to specify a heatmap for ggplot
geom_text(aes(label = round(Median_Scaled_Concentration, 2))) # adding concentration values as text, rounding to two values after the decimal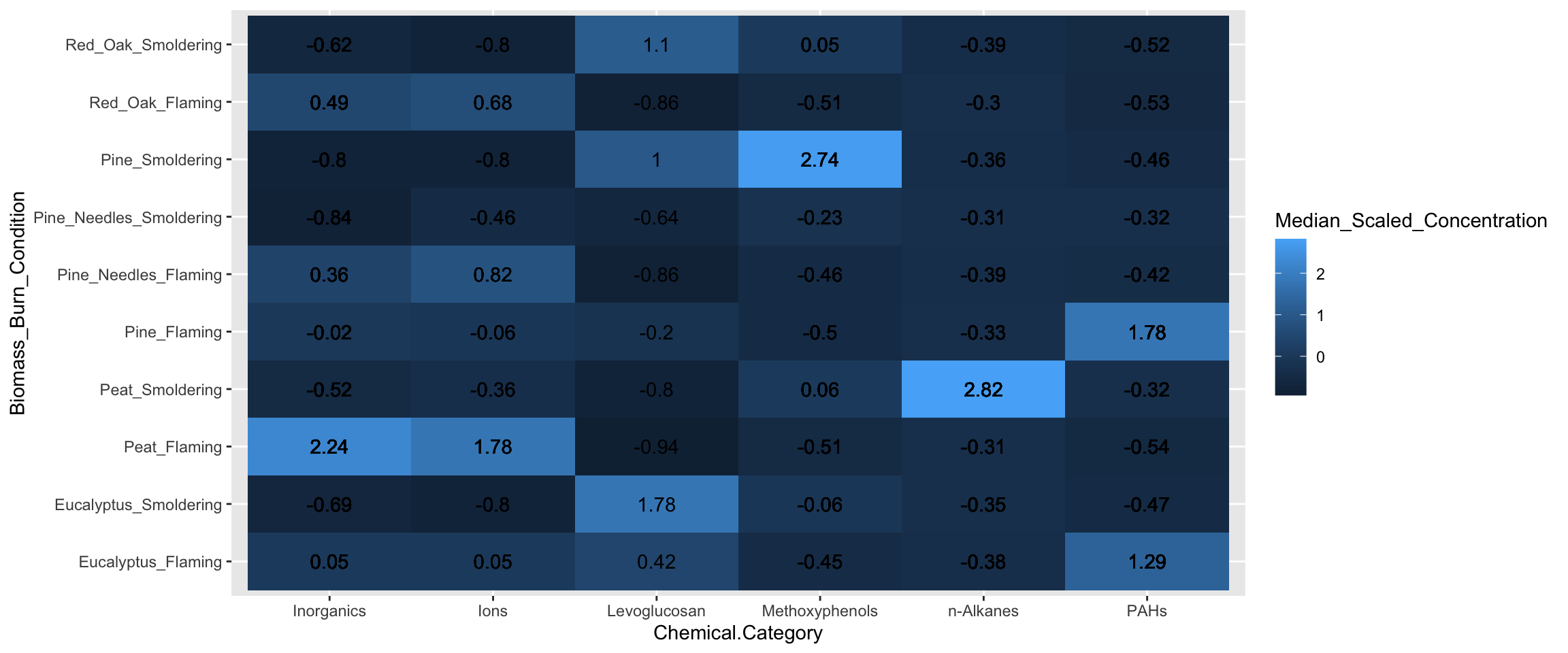
Answer to Environmental Health Question 3
With this, we can answer Environmental Health Question #3: Under which biomass burn conditions are concentrations of certain chemical categories the highest?
Answer: Peat flaming has the highest concentrations of inorganics and ions. Eucalyptus smoldering has the highest concentrations of levoglucosans. Pine smoldering has the highest concentrations of methoxyphenols. Peat smoldering has the highest concentrations of n-alkanes. Pine needles smoldering has highest concentrations of PAHs.
This same heatmap can be achieved another way using the pheatmap() function from the pheatmap package. Using this function requires us to use a wide dataset, which we need to create. It will contain Chemical.Category, Biomass_Burn_Condition and Scaled_Chemical_Concentration.
heatmap_df2 = scaled_longer_smoke_data %>%
group_by(Biomass_Burn_Condition, Chemical.Category) %>%
# using the summarize function instead of mutate function as was done previously since we only need the median values now
summarize(Median_Scaled_Concentration = median(Scaled_Chemical_Concentration)) %>%
# transforming the data to a wide format
pivot_wider(id_cols = Biomass_Burn_Condition, names_from = "Chemical.Category",
values_from = "Median_Scaled_Concentration") %>%
# converting the chemical names to row names
column_to_rownames(var = "Biomass_Burn_Condition")
head(heatmap_df2)## Inorganics Ions Levoglucosan Methoxyphenols
## Eucalyptus_Flaming 0.05405359 0.05273246 0.4208870 -0.44781893
## Eucalyptus_Smoldering -0.68595076 -0.80160192 1.7772753 -0.06449444
## Peat_Flaming 2.24332901 1.77515899 -0.9383328 -0.51488738
## Peat_Smoldering -0.51860591 -0.36146158 -0.8041211 0.05720971
## Pine_Flaming -0.02063532 -0.05999543 -0.1992054 -0.50269422
## Pine_Needles_Flaming 0.36405527 0.82229035 -0.8570130 -0.46331332
## PAHs n-Alkanes
## Eucalyptus_Flaming 1.2885776 -0.3790357
## Eucalyptus_Smoldering -0.4724635 -0.3465132
## Peat_Flaming -0.5369746 -0.3093608
## Peat_Smoldering -0.3162278 2.8238921
## Pine_Flaming 1.7825403 -0.3347765
## Pine_Needles_Flaming -0.4179505 -0.3850613Now let’s generate the same heatmap this time using the pheatmap() function:
pheatmap(heatmap_df2,
# removing the clustering option from both rows and columns
cluster_rows = FALSE, cluster_cols = FALSE,
# adding the values for each cell, making those values black, and changing the font size
display_numbers = TRUE, number_color = "black", fontsize = 12) 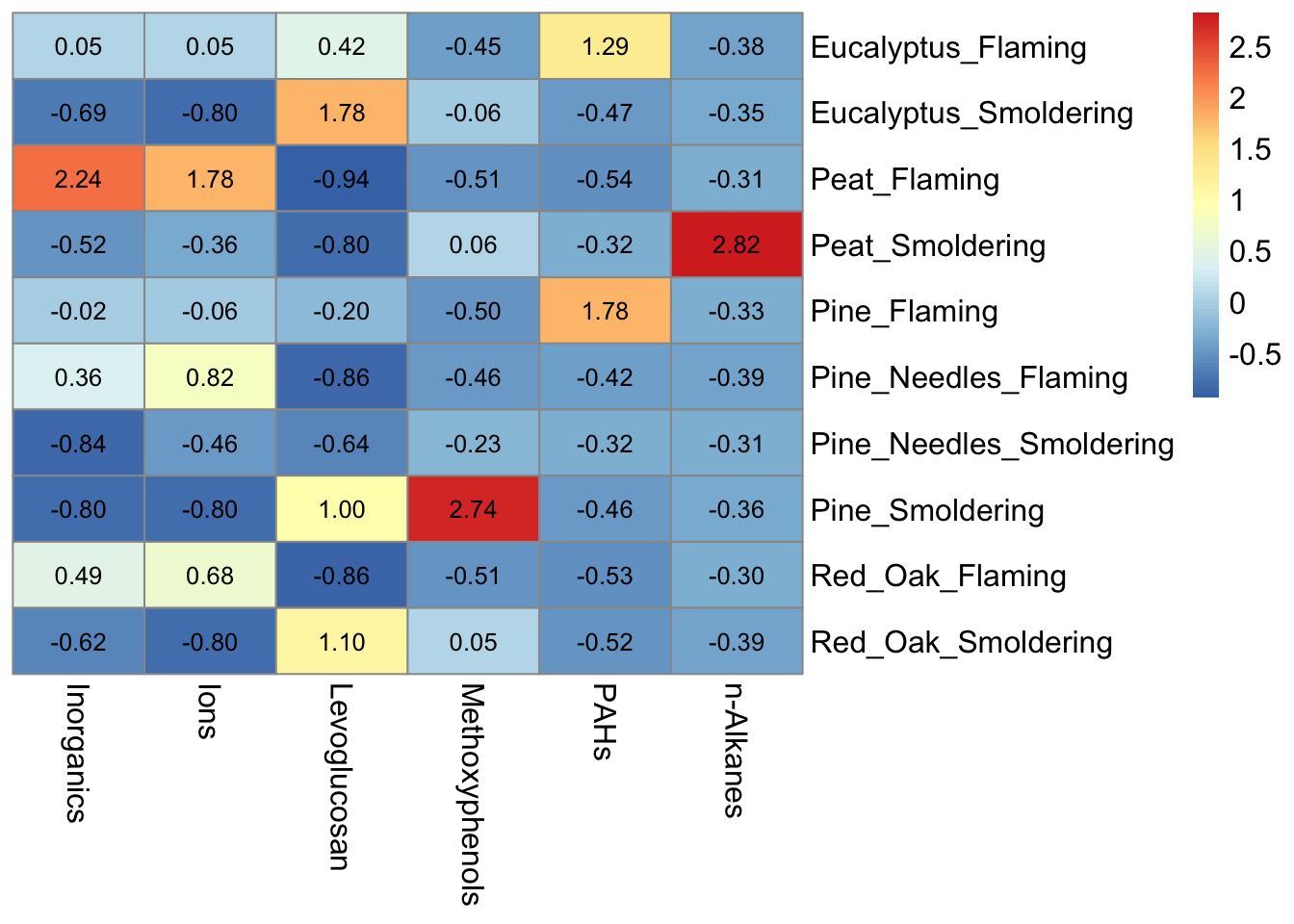
Notice that the pheatmap() function does not include axes or legend titles as with ggplot(), however those can be added to the figure after exporting from R in MS Powerpoint or Adobe. Additional parameters, including cluster_rows, for the pheatmap() function are discussed further in TAME 2.0 Module 5.5 Unsupervised Machine Learning Part 2: Additional Clustering Applications. For basic heatmaps like the ones shown here, ggplot() or pheatmap() can both be used however, both have their pros and cons. For example, ggplot() figures tend to be more customizable and easily combined with other figures, while pheatmap() has additional parameters built into the function that can make plotting certain features advantageous like clustering.
Concluding Remarks
In conclusion, this training module provided example code to create highly customizable data visualizations using ggplot2 pertinent to environmental health research.
Replicate the figure below! The heatmap still visualizes the median chemical concentrations, but this time we’re separating the burn conditions, allowing us to determine if the concentrations of chemicals released are contingent upon the burn condition.
For additional figures available and to view aspects of figures that can be changed in GGplot2, check out this GGPlot2 Cheat Sheet. You might need it to make this figure!
Hint 1: Use the separate() function from tidyverse to split Biomass_Burn_Condition into Biomass and Burn_Condition.
Hint 2: Use the function facet_wrap() within ggplot() to separate the heatmaps by Burn_Condition.