4.3 Data Import from PDF Sources
This training module was developed by Elise Hickman, Alexis Payton, and Julia E. Rager.
All input files (script, data, and figures) can be downloaded from the UNC-SRP TAME2 GitHub website.
Introduction to Training Module
Most tutorials for R rely on importing .csv, .xlsx, or .txt files, but there are numerous other file formats that can store data, and these file formats can be more difficult to import into R. PDFs can be particularly difficult to interface with in R because they are not formatted with defined rows/columns/cells as is done in Excel or .csv/.txt formatting. In this module, we will demonstrate how to import data from from PDFs into R and format it such that it is amenable for downstream analyses or export as a table. Familiarity with tidyverse, for loops, and functions will make this module much more approachable, so be sure to review TAME 2.0 Modules 2.3 Data Manipulation and Reshaping and 2.4 Improving Coding Efficiencies if you need a refresher.
Overview of Example Data
To demonstrate import of data from PDFs, we will be leveraging two example datasets, described in more detail in their respective sections later on in the module.
PDFs generated by Nanoparticle Tracking Analysis (NTA), a technique used to quantify the size and distribution of particles (such as extracellular vesicles) in a sample. We will be extracting data from an experiment in which epithelial cells were exposed to four different environmental chemicals or a vehicle control, and secreted particles were isolated and characterized using NTA.
A PDF containing information about variables collected as part of a study whose samples are part of NIH’s BioLINCC Repository.
Training Module’s Environmental Health Questions
This training module was specifically developed to answer the following environmental health questions:
- Which chemical(s) increase and decrease the concentration of particles secreted by epithelial cells?
- How many variables total are available to us to request from the study whose data are store in the repository, and what are these variables?
Importing Data from Many Single PDFs with the Same Formatting
Getting Familiar with the Example Dataset
The following example is based on extracting data from PDFs generated by Nanoparticle Tracking Analysis (NTA), a technique used to quantify the size and distribution of particles in a sample. Each PDF file is associated with one sample, and each PDF contains multiple values that we want to extract. Although this is a very specific type of data, keep in mind that this general approach can be applied to any data stored in PDF format - you will just need to make modifications based on the layout of your PDF file!
For this example, we will be extracting data from 5 PDFs that are identically formatted but contain information unique to each sample. The samples represent particles isolated from epithelial cell media following an experiment where cells were exposed to four different environmental chemicals (labeled “A”, “B”, “C”, and “D”) or a vehicle control (labeled “Ctrl”).
Here is what a full view of one of the PDFs looks like, with values we want to extract highlighted in yellow:
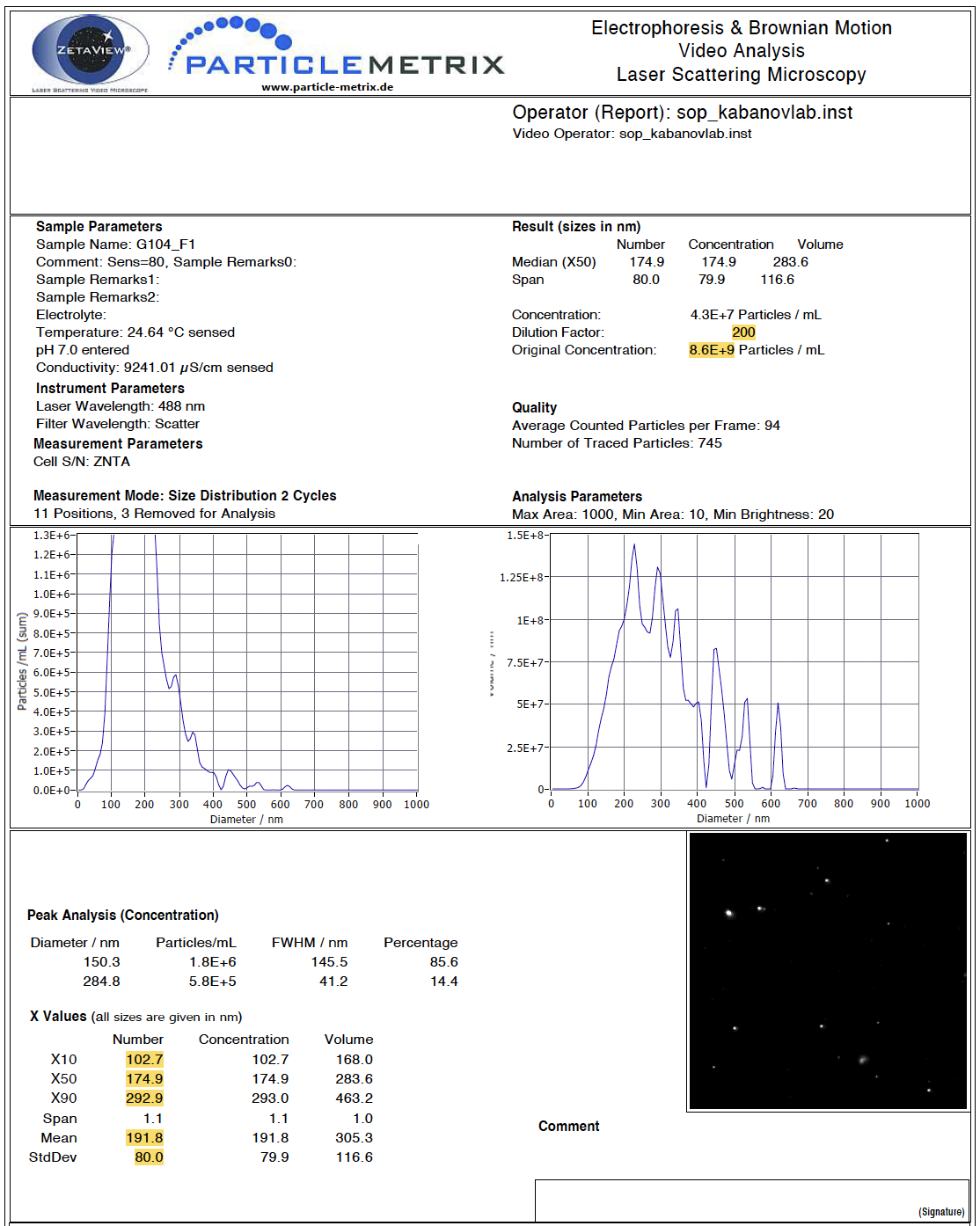
Our goal is to extract these values and end up with a dataframe that looks like this, with each sample in a row and each variable in a column:
If your files are not already named in a way that reflects unique sample information, such as the date of the experiment or sample ID, update your file names to contain this information before proceeding with the script. Here are the names for the example PDF files:

Workspace Preparation and Data Import
Installing and loading required R packages
If you already have these packages installed, you can skip this step, or you can run the below code which checks installation status for you. We will be using the pdftools and tm packages to extract text from the PDF. And instead of using head() to preview dataframes, we will be using the function datatable() from the DT package. This function produces interactive tables and generates better formatting for viewing dataframes that have long character strings (like the ones we will be viewing in this section).
if (!requireNamespace("pdftools"))
install.packages("pdftools")
if (!requireNamespace("tm"))
install.packages("tm")
if (!requireNamespace("DT"))
install.packages("DT")
if (!requireNamespace("janitor"))
install.packages("janitor")Next, load the packages.
Initial data import from PDF files
The following code stores the file names of all of the files in your directory that end in .pdf. To ensure that only PDFs of interest are imported, consider making a subfolder within your directory containing only the PDF extraction script file and the PDFs you want to extract data from.
We can see that each of our file names are now contained in the list.
## [1] "20230214_0002_Expt1_A_size_488.pdf"
## [2] "20230214_0006_Expt1_Ctrl_size_488.pdf"
## [3] "20230214_0014_Expt1_C_size_488.pdf"
## [4] "20230214_0023_Expt1_D_size_488.pdf"
## [5] "20230214_0024_Expt1_B_size_488.pdf"Next, we need to make a dataframe to store the extracted data. The PDF Identifier column will store the file name, and the Text column will store extracted text from the PDF.
The following code uses a for loop to loop through each file (as stored in the pdf_list vector) and extract the text from the PDF. Sometimes this code generates duplicates, so we will also remove the duplicates with distinct().
for (i in 1:length(pdf_list)){
# Iterating through each pdf file and separating each line of text
document_text = pdf_text(paste("./Chapter_4/4_3_PDF_Import/", pdf_list[i], sep = "")) %>%
strsplit("\n")
# Saving the name of each PDF file and its text
document = data.frame("PDF Identifier" = gsub(x = pdf_list[i], pattern = ".pdf", replacement = ""),
"Text" = document_text, stringsAsFactors = FALSE)
colnames(document) <- c("PDF Identifier", "Text")
# Appending the new text data to the dataframe
pdf_raw <- rbind(pdf_raw, document)
}
pdf_raw <- pdf_raw %>%
distinct()The new dataframe contains the data from all of the PDFs, with the PDF Identifier column containing the name of the input PDF file that corresponds to the text in the column next to it.
Extracting Variables of Interest
Specific variables of interest can be extracted from the pdf_raw dataframe by filtering the dataframe for rows that contain a specific character string. This character string could be the variable of interest (if that word or set of words is unique and only occurs in that one place in the document) or a character string that occurs in the same line of the PDF as your variable of interest. Examples of both of these approaches are shown below.
It is important to note that there can be different numbers of spaces in each row and after each semicolon, which will change the sep argument for each variable. For example, there are a different number of spaces after the semicolon for “Dilution Factor” than there are for “Concentration” (see above PDF screen shot for reference). We will work through an example for the first variable of interest, dilution factor, in detail.
First, we can see what the dataframe looks like when we just filter rows based on keeping only rows that contain the string “Dilution Factor” in the text column using the grepl() function.
dilution_factor_df <- pdf_raw %>%
filter(grepl("Dilution Factor", Text))
datatable(dilution_factor_df)The value we are trying to extract is at the end of a long character string. We will want to use the tidyverse function separate() to isolate those values, but we need to know what part of the character string will separate the dilution factor values from the rest of the text. To determine this, we can call just one of the data cells and copy the semicolon and following spaces for use in the separate() function.
## [1] " Temperature: 24.64 °C sensed Dilution Factor: 200"Building on top of the previous code, we can now separate the dilution factor value from the rest of the text in the string. The separate() function takes an input data column and separates it into two or more columns based on the character passed to the separation argument. Here, everything before the separation string is discarded by setting the first new column to NA. Everything after the separation string will be stored in a new column called Dilution Factor, The starting Text column is removed by default.
dilution_factor_df <- pdf_raw %>%
filter(grepl("Dilution Factor", Text)) %>%
separate(Text, into = c(NA, "Dilution Factor"), sep = ": ")
datatable(dilution_factor_df)For the “Original Concentration” variable, we filter rows by the string “pH” because the word concentration is found in multiple locations in the document.
concentration_df = pdf_raw %>%
filter(grepl("pH", Text)) %>%
separate(Text, c(NA, "Concentration"), sep = ": ")
datatable(concentration_df)With the dilution factor variable, there were no additional characters after the value of interest, but here, “Particles / mL” remains and needs to be removed so that the data can be used in downstream analyses. We can add an additional cleaning step to remove “Particles / mL” from the data and add the units to the column title. sep = " P" refers to the space before and first letter of the string to be removed.
concentration_df = pdf_raw %>%
filter(grepl("pH", Text)) %>%
separate(Text, c(NA, "Concentration"), sep = ": ") %>%
separate(Concentration, c("Concentration (Particles/ mL)", NA), sep = " P")
datatable(concentration_df)Next, we want to extract size distribution data from the lower table. Note that the space in the first separate() function comes from the space between the “Number” and “Concentration” column in the string, and the space in the second separate() function comes from the space between the variable name and the number of interest. We can also convert values to numeric since they are currently stored as characters.
size_distribution_df = pdf_raw %>%
filter(grepl("X10", Text)| grepl("X50 ", Text)| grepl("X90", Text) | grepl("Mean", Text)| grepl("StdDev", Text)) %>%
separate(Text, c("Text", NA), sep = " ") %>%
separate(Text, c("Text", "Size"), sep = " ") %>%
mutate(Size = as.numeric(Size)) %>%
pivot_wider(names_from = Text, values_from = Size)
datatable(size_distribution_df)Creating the final dataframe
Now that we have created dataframes for all of the variables that we are interested in, we can join them together into one final dataframe.
# Make list of all dataframes to include
all_variables <- list(dilution_factor_df, concentration_df, size_distribution_df)
# Combine dataframes using reduce function. Sometimes, duplicate rows are generated by full_join.
full_df = all_variables %>%
reduce(full_join, by = "PDF Identifier") %>%
distinct()
# View new dataframe
datatable(full_df)For easier downstream analysis, the last step is to separate the PDF Identifier column into an informative sample ID that matches up with other experimental data.
final_df <- full_df %>%
separate('PDF Identifier',
# Split sample identifier column into new columns, retaining the original column
into = c("Date", "FileNumber", "Experiment Number", "Sample_ID", "Size", "Wavelength"), sep = "_", remove = FALSE) %>%
select(-c(FileNumber, Size)) %>% # Remove uninformative columns
mutate(across('Dilution Factor':'StdDev', as.numeric)) # Change variables to numeric where appropriate
datatable(final_df)Let’s make a graph to help us answer Environmental Health Question 1.
theme_set(theme_bw())
data_for_graphing <- final_df %>%
clean_names()
data_for_graphing$sample_id <- factor(data_for_graphing$sample_id, levels = c("Ctrl", "A", "B", "C", "D"))
ggplot(data_for_graphing, aes(x = sample_id, y = concentration_particles_m_l)) +
geom_bar(stat = "identity", fill = "gray70", color = "black") +
ylab("Particle Concentration (Particles/mL)") +
xlab("Exposure")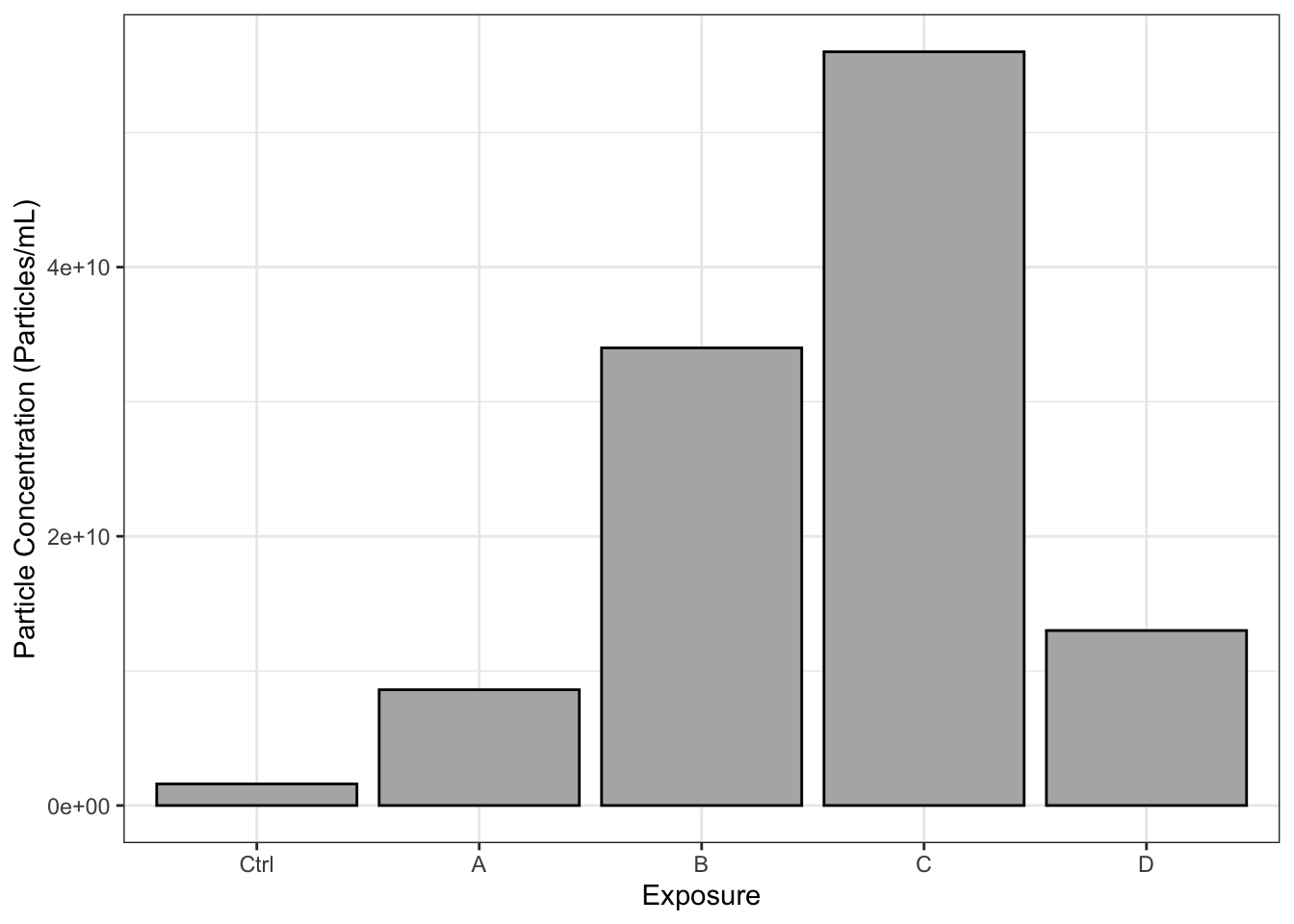
With this, we can answer Environmental Health Question #1: Which chemical(s) increase and decrease the concentration of particles secreted by epithelial cells?
Answer: Chemicals B and C appear to increase the concentration of secreted particles. However, additional replicates of this experiment are needed to assess statistical significance.
Importing Data Stored in PDF Tables
The above workflow is useful if you just want to extract a few specific values from PDFs, but isn’t as useful if data are already in a table format in a PDF. The tabulapdf package provides helpful functions for extracting dataframes from tables in PDF format.
Getting Familiar with the Example Dataset
The following example is based on extracting dataframes from a long PDF containing many individual data tables. This particular PDF came from the NIH’s BioLINCC Repository and details variables that researchers can request from the repository. Variables are part of larger datasets that contain many variables, with each dataset in a separate table. All of the tables are stored in one PDF file, and some of the tables are longer than one page (this will become relevant later on!). Similar to the first PDF workflow, remember that this is a specific example intended to demonstrate how to work through extracting data from PDFs. Modifications will need to be made for differently formatted PDFs.
Here is what the first three pages of our 75-page starting PDF look like:
If we zoom in a bit more on the first page, we can see that the dataset name is defined in bold above each table. This formatting is consistent throughout the PDF.
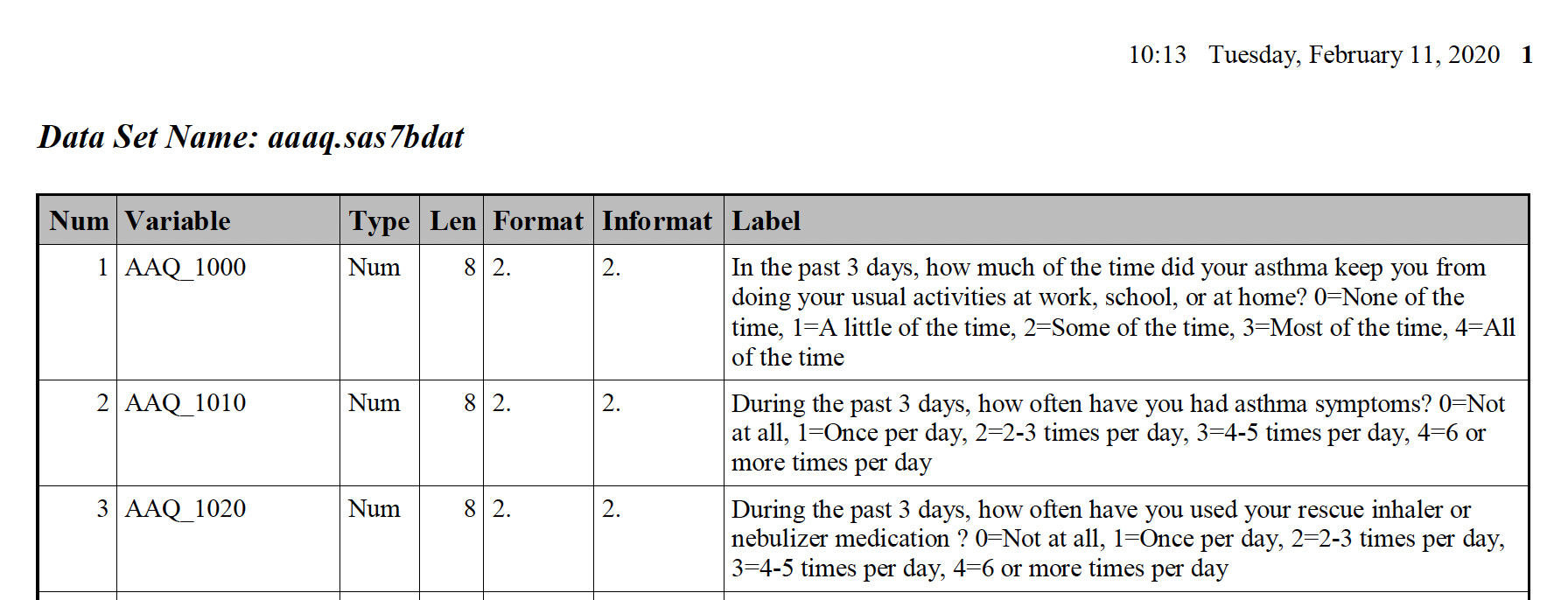
The zoomed in view also allows us to see the columns and their contents more clearly. Some are more informative than others. The columns we are most interested in are listed below along with a description to guide you through the contents.
Num: The number assigned to each variable in the dataset. This numbering restarts with 1 for each table.Variable: The variable name.Type: The type (or class) of the variable, either numeric or character.Label: A description of the variable and values associated with the variable.
After extracting the data, we want to end up with a dataframe that contains all of the variables, their corresponding columns, and a column that indicates which dataset the variable is associated with:
Workspace Preparation and Data Import
Installing and loading required R packages
Similar to previous sections, we need to install and load a few packages before proceeding. The tabulapdf package needs to be installed in a specific way as shown below and can sometimes be difficult to install on Macs. If errors are produced, follow the troubleshooting tips outlined in this Stack Overflow solution.
# To install all of the packages except for tabulapdf
if (!requireNamespace("stringr"))
install.packages("stringr")
if (!requireNamespace("pdftools"))
install.packages("pdftools")
if (!requireNamespace("rJava"))
install.packages("rJava")# To install tabulapdf
if (!require("remotes")) {
install.packages("remotes")
}
library(remotes)
remotes::install_github(c("ropensci/tabulizerjars", "ropensci/tabulapdf"), force=TRUE, INSTALL_opts = "--no-multiarch")Load packages:
Initial data import from PDF file
The extract_tables() function automatically extracts tables from PDFs and stores them as tibbles (a specific tidyverse data structure similar to a dataframe) within a list. One table is extracted per page, even if the table spans multiple pages. This line of code can take a few seconds to run depending on the length of your PDF.
tables <-tabulapdf::extract_tables("Chapter_4/4_3_PDF_Import/Module4_3_InputData4.pdf", output = "tibble")Glimpsing the first three elements in the tables list, we can see that each list element is a dataframe containing the columns from the PDF tables.
## List of 3
## $ : spc_tbl_ [30 × 7] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## ..$ Num : num [1:30] 1 NA NA NA 2 NA NA 3 NA NA ...
## ..$ Variable: chr [1:30] "AAQ_1000" NA NA NA ...
## ..$ Type : chr [1:30] "Num" NA NA NA ...
## ..$ Len : num [1:30] 8 NA NA NA 8 NA NA 8 NA NA ...
## ..$ Format : chr [1:30] "2." NA NA NA ...
## ..$ Informat: chr [1:30] "2." NA NA NA ...
## ..$ Label : chr [1:30] "In the past 3 days, how much of the time did your asthma keep you from" "doing your usual activities at work, school, or at home? 0=None of the" "time, 1=A little of the time, 2=Some of the time, 3=Most of the time, 4=All" "of the time" ...
## ..- attr(*, "spec")=
## .. .. cols(
## .. .. Num = col_double(),
## .. .. Variable = col_character(),
## .. .. Type = col_character(),
## .. .. Len = col_double(),
## .. .. Format = col_character(),
## .. .. Informat = col_character(),
## .. .. Label = col_character()
## .. .. )
## ..- attr(*, "problems")=<externalptr>
## $ : spc_tbl_ [46 × 7] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## ..$ Num : num [1:46] 1 2 3 4 5 6 NA NA 7 NA ...
## ..$ Variable: chr [1:46] "ABP_1000" "ABP_1010" "ABP_1020" "ABP_1030" ...
## ..$ Type : chr [1:46] "Num" "Num" "Num" "Num" ...
## ..$ Len : num [1:46] 8 8 8 8 8 8 NA NA 8 NA ...
## ..$ Format : num [1:46] 2 2 2 2 2 2 NA NA 2 NA ...
## ..$ Informat: num [1:46] 2 2 2 2 2 2 NA NA 2 NA ...
## ..$ Label : chr [1:46] "Are you currently retired? 1=Yes,0=No" "Are you retired because of asthma? 1=Yes,0=No" "Are you currently unemployed? 1=Yes,0=No" "Are you unemployed because of asthma? 1=Yes,0=No" ...
## ..- attr(*, "spec")=
## .. .. cols(
## .. .. Num = col_double(),
## .. .. Variable = col_character(),
## .. .. Type = col_character(),
## .. .. Len = col_double(),
## .. .. Format = col_double(),
## .. .. Informat = col_double(),
## .. .. Label = col_character()
## .. .. )
## ..- attr(*, "problems")=<externalptr>
## $ : spc_tbl_ [21 × 7] (S3: spec_tbl_df/tbl_df/tbl/data.frame)
## ..$ Num : num [1:21] 20 NA NA 21 NA NA 22 NA NA 23 ...
## ..$ Variable: chr [1:21] "ABP_1190" NA NA "ABP_1200" ...
## ..$ Type : chr [1:21] "Num" NA NA "Num" ...
## ..$ Len : num [1:21] 8 NA NA 8 NA NA 8 NA NA 8 ...
## ..$ Format : chr [1:21] "2." NA NA "2." ...
## ..$ Informat: chr [1:21] "2." NA NA "2." ...
## ..$ Label : chr [1:21] "How much bother is the worry that you will have an asthma attack when" "visiting a new place? 0=No bother at all, 1=Minor irritation, 2=Slight" "bother, 3=Moderate bother, 4=A lot of bother, 5=Makes my life a misery" "How much bother is the worry that you will catch a cold? 0=No bother at" ...
## ..- attr(*, "spec")=
## .. .. cols(
## .. .. Num = col_double(),
## .. .. Variable = col_character(),
## .. .. Type = col_character(),
## .. .. Len = col_double(),
## .. .. Format = col_character(),
## .. .. Informat = col_character(),
## .. .. Label = col_character()
## .. .. )
## ..- attr(*, "problems")=<externalptr>Exploring further, here is how each dataframe is formatted:
Notice that, although the dataframe format mirrors the PDF table format, the label column is stored across multiple rows with NAs in the other columns of that row because the text was across multiple lines. In our final dataframe, we will want the entire block of text in one cell. We can also remove the “Len”, “Format”, and “Informat” columns because they are not informative and they are not found in every table. Next, we will walk through how to clean up this table using a series of steps in tidyverse.
Cleaning dataframes
First, we will select the columns we are interested in and use the fill() function to change the NAs in the “Num” column so that each line of text in the “Label” column has the correct “Num” value in the same row.
cleaned_table1 <- data.frame(tables[[1]]) %>% # Extract the first table in the list
# Select only the columns of interest
select(c(Num, Variable, Type, Label)) %>%
# Change the "Num" column to numeric, which is required for the fill function
mutate(Num = as.numeric(Num)) %>%
# Fill in the NAs in the "Num" column down the column
fill(Num, .direction = "down")
datatable(cleaned_table1)We still need to move all of the Label text for each variable into one cell in one row instead of across multiple rows. For this, we can use the unlist() function. Here is a demonstration of how the unlist() function works using just the first variable:
cleaned_table1_var1 <- cleaned_table1 %>%
# Filter dataframe to just contain rows associated with the first variable
filter(Num == 1) %>%
# Paste all character strings in the Label column with a space in between them into a new column called "new_label"
mutate(new_label = paste(unlist(Label), collapse = " "))
datatable(cleaned_table1_var1)We now have all of the text we want in one cell, but we have duplicate rows that we don’t need. We can get rid of these rows by assigning blank values “NA” and then omitting rows that contain NAs.
cleaned_table1_var1 <- cleaned_table1_var1 %>%
mutate(across(Variable, na_if, "")) %>%
na.omit()
datatable(cleaned_table1_var1)We need to apply this code to the whole dataframe and not just one variable, so we can add group_by(Num) to our cleaning workflow, followed by the code we just applied to our filtered dataframe.
cleaned_table1 <- data.frame(tables[[1]]) %>% # Extract the first table in the list
# Select only the columns of interest
select(c(Num, Variable, Type, Label)) %>%
# Change the "Num" column to numeric, which is required for the fill function
mutate(Num = as.numeric(Num)) %>%
# Fill in the NAs in the "Num" column down the column
fill(Num, .direction = "down") %>%
# Group by variable number
group_by(Num) %>%
# Unlist the text replace the text in the "Label" column with the unlisted text
mutate(Label = paste(unlist(Label), collapse =" ")) %>%
# Make blanks in the "Variable" column into NAs
mutate(across(Variable, na_if, "")) %>%
# Remove rows with NAs
na.omit()
datatable(cleaned_table1)Ultimately, we need to clean up each dataframe in the list the same way, and we need all of the dataframes to be in one dataframe, instead of in a list. There are a couple of different ways to do this. Both rely on the code shown above for cleaning up each dataframe. Option #1 uses a for loop, while Option #2 uses application of a function on the list of dataframes. Both result in the same ending dataframe!
Option #1
# Create a dataframe for storing variables
variables <- data.frame()
# Make a for loop to format each dataframe and add it to the variables
for (i in 1:length(tables)) {
table <- data.frame(tables[[i]]) %>%
select(c(Num, Variable, Type, Label)) %>%
mutate(Num = as.numeric(Num)) %>%
fill(Num, .direction = "down") %>%
group_by(Num) %>%
mutate(Label = paste(unlist(Label), collapse =" ")) %>%
mutate(across(Variable, na_if, "")) %>%
na.omit()
variables <- bind_rows(variables, table)
}
# View resulting dataframe
datatable(variables)Option #2
# Write a function that applies all of the cleaning steps to an dataframe (output = cleaned dataframe)
clean_tables <- function(data) {
data <- data %>%
select(c(Num, Variable, Type, Label)) %>%
mutate(Num = as.numeric(Num)) %>%
fill(Num, .direction = "down") %>%
group_by(Num) %>%
mutate(Label = paste(unlist(Label), collapse =" ")) %>%
mutate(across(Variable, na_if, "")) %>%
na.omit()
return(data)
}
# Apply the function over each table in the list of tables
tables_clean <- lapply(X = tables, FUN = clean_tables)
# Unlist the dataframes and combine them into one dataframe
tables_clean_unlisted <- do.call(rbind, tables_clean)
# View resulting dataframe
datatable(tables_clean_unlisted)Adding Dataset Names
We now have a dataframe with all of the information from the PDFs contained in one long table. However, now we need to add back in the label on top of each table. We can’t do this with the tabulapdf package because the name isn’t stored in the table. But we can use the pdftools package for this!
First, we will read in the pdf using the PDF tools package. This results in a vector containing a long character string for each page of the PDF. Notice a few features of these character strings:
- Each line is separated by
\n - Elements [1] and [2] of the vector contain the text “dataset Name:”, while element [3] does not because the third page was a continuation of the table from the second page and therefore did not have a table title.
## [1] " 10:13 Tuesday, February 11, 2020 1\n\n\nData Set Name: aaaq.sas7bdat\n\nNum Variable Type Len Format Informat Label\n 1 AAQ_1000 Num 8 2. 2. In the past 3 days, how much of the time did your asthma keep you from\n doing your usual activities at work, school, or at home? 0=None of the\n time, 1=A little of the time, 2=Some of the time, 3=Most of the time, 4=All\n of the time\n 2 AAQ_1010 Num 8 2. 2. During the past 3 days, how often have you had asthma symptoms? 0=Not\n at all, 1=Once per day, 2=2-3 times per day, 3=4-5 times per day, 4=6 or\n more times per day\n 3 AAQ_1020 Num 8 2. 2. During the past 3 days, how often have you used your rescue inhaler or\n nebulizer medication ? 0=Not at all, 1=Once per day, 2=2-3 times per day,\n 3=4-5 times per day, 4=6 or more times per day\n 4 AAQ_1030 Num 8 2. 2. During the past 3 days, how many total times did your asthma symptoms\n wake you up from sleep? 0=Not at all, 1=1 time in the last 3 days, 2=2-3\n times in the last 3 days, 3=4-5 times in the last 3 days, 4=>=6 times in the\n last 3 days\n 5 AAQ_1040 Num 8 2. 2. How would you rate the amount of impairment you have experienced due\n to your asthma in the past 3 days? 0=No impairment, 1=Mild impairment,\n 2=Moderate impairment, 3=Severe impairment, 4=Very severe impairment\n 6 AAQ_1050 Num 8 2. 2. How stressed or frightened were you by your asthma symptoms in the past\n 3 days? 0=Not at all, 1=Mildly, 2=Moderately, 3=Severely, 4=Very\n severely\n 7 AAQ_1060 Num 8 2. 2. Why do you think your asthma was worse in the past 3 days compared to\n what is normal for you? 0=I have not been worse over the past 3 days. My\n asthma symptoms have been usual., 1=Common cold, 2=Allergies,\n 3=Pollution or chemical irritant, 4=Too little asth\n 8 VNUM_C Char 3 $3. $3. Visit Number (character)\n 9 VNUM Num 8 Visit Number (numeric)\n 10 VDATE Num 8 Number of days from Visit 1 to this visit\n 11 RAND_ID Char 6 Randomized Master ID\n 12 ENROLL_TYPE Char 15 Enrollment Type (Screen Fail, Randomized, Healthy Control)\n 13 ENROLL_ORDER Num 8 Enrollment Order Number\n"
## [2] " 10:13 Tuesday, February 11, 2020 2\n\n\n\nData Set Name: abp.sas7bdat\n\nNum Variable Type Len Format Informat Label\n 1 ABP_1000 Num 8 2. 2. Are you currently retired? 1=Yes,0=No\n 2 ABP_1010 Num 8 2. 2. Are you retired because of asthma? 1=Yes,0=No\n 3 ABP_1020 Num 8 2. 2. Are you currently unemployed? 1=Yes,0=No\n 4 ABP_1030 Num 8 2. 2. Are you unemployed because of asthma? 1=Yes,0=No\n 5 ABP_1040 Num 8 2. 2. Do you get paid to do work? 1=Yes,0=No\n 6 ABP_1050 Num 8 2. 2. How much does your asthma bother you at your paid work? 0=No bother\n at all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of\n bother, 5=Makes my life a misery\n 7 ABP_1060 Num 8 2. 2. Overall, how much does your asthma bother you when you do jobs\n around the house? 0=No bother at all, 1=Minor irritation, 2=Slight bother,\n 3=Moderate bother, 4=A lot of bother, 5=Makes my life a misery,\n 0=None of these really apply to me\n 8 ABP_1070 Num 8 2. 2. Overall, how much does your asthma bother your social life? 0=No bother\n at all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of\n bother, 5=Makes my life a misery\n 9 ABP_1080 Num 8 2. 2. Overall, how much does your asthma bother your personal life? 0=No\n bother at all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother,\n 4=A lot of bother, 5=Makes my life a misery, 0=None of these really\n apply to me\n 10 ABP_1090 Num 8 2. 2. Are you involved in leisure activities, such as: walking for pleasure,\n sports, exercise, travelling, taking vacations? 1=Yes,0=No\n 11 ABP_1100 Num 8 2. 2. When involved in leisure activities, how much does your asthma bother\n you? 0=No bother at all, 1=Minor irritation, 2=Slight bother, 3=Moderate\n bother, 4=A lot of bother, 5=Makes my life a misery\n 12 ABP_1110 Num 8 2. 2. Would you say that you can't do some of these sorts of things because of\n asthma? 1=Yes,0=No\n 13 ABP_1120 Num 8 2. 2. How much does your asthma bother you when you sleep? 0=No bother at\n all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of\n bother, 5=Makes my life a misery\n 14 ABP_1130 Num 8 2. 2. How much does the cost of your asthma medicines bother you? 0=No\n bother at all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother,\n 4=A lot of bother, 5=Makes my life a misery\n 15 ABP_1140 Num 8 2. 2. Do you get free prescriptions? 1=Yes,0=No\n 16 ABP_1150 Num 8 2. 2. How much does the inconvenience or embarrassment of taking your\n asthma medicines bother you? 0=No bother at all, 1=Minor irritation,\n 2=Slight bother, 3=Moderate bother, 4=A lot of bother, 5=Makes my life\n a misery\n 17 ABP_1160 Num 8 2. 2. How much do coughs and colds bother you? 0=No bother at all, 1=Minor\n irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of bother,\n 5=Makes my life a misery, 0=None of these really apply to me\n 18 ABP_1170 Num 8 2. 2. Feeling upset is also a bother. Does your asthma make you feel anxious,\n depressed, tired, or helpless? 1=Yes,0=No\n 19 ABP_1180 Num 8 2. 2. Feeling upset is also a bother. Does your asthma make you feel anxious,\n depressed, tired, or helpless? 0=No bother at all, 1=Minor irritation,\n 2=Slight bother, 3=Moderate bother, 4=A lot of bother, 5=Makes my life\n a misery\n"
## [3] " 10:13 Tuesday, February 11, 2020 3\n\n\nNum Variable Type Len Format Informat Label\n 20 ABP_1190 Num 8 2. 2. How much bother is the worry that you will have an asthma attack when\n visiting a new place? 0=No bother at all, 1=Minor irritation, 2=Slight\n bother, 3=Moderate bother, 4=A lot of bother, 5=Makes my life a misery\n 21 ABP_1200 Num 8 2. 2. How much bother is the worry that you will catch a cold? 0=No bother at\n all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of\n bother, 5=Makes my life a misery\n 22 ABP_1210 Num 8 2. 2. How much bother is the worry that you will let others down? 0=No bother\n at all, 1=Minor irritation, 2=Slight bother, 3=Moderate bother, 4=A lot of\n bother, 5=Makes my life a misery\n 23 ABP_1220 Num 8 2. 2. How much bother is the worry that your health may get worse in the\n future? 0=No bother at all, 1=Minor irritation, 2=Slight bother,\n 3=Moderate bother, 4=A lot of bother, 5=Makes my life a misery\n 24 ABP_1230 Num 8 2. 2. How much bother is the worry that you won't be able to cope with an\n asthma attack? 0=No bother at all, 1=Minor irritation, 2=Slight bother,\n 3=Moderate bother, 4=A lot of bother, 5=Makes my life a misery\n 25 VNUM_C Char 3 $3. $3. Visit Number (character)\n 26 VNUM Num 8 Visit Number (numeric)\n 27 VDATE Num 8 Number of days from Visit 1 to this visit\n 28 RAND_ID Char 6 Randomized Master ID\n 29 ENROLL_TYPE Char 15 Enrollment Type (Screen Fail, Randomized, Healthy Control)\n 30 ENROLL_ORDER Num 8 Enrollment Order Number\n"Similar to the table cleaning section, we will work through an example of extracting the text of interest from one of these character vectors, then apply the same code to all of the character vectors. First, we will select just the first element in the vector and make it into a dataframe.
# Create dataframe
dataset_name_df_var1 <- data.frame(strsplit(table_names[1], "\n"))
# Clean column name
colnames(dataset_name_df_var1) <- c("Text")
# View dataframe
datatable(dataset_name_df_var1)Next, we will extract the dataset name using the same approach used in extracting values from the nanoparticle tracking example above and assign the name to a variable. We filter by the string “Data Set Name” because this is the start of the text string in the row where our dataset name is stored and is the same across all of our datasets.
# Create dataframe
dataset_name_df_var1 <- dataset_name_df_var1 %>%
filter(grepl("Data Set Name", dataset_name_df_var1$Text)) %>%
separate(Text, into = c(NA, "dataset"), sep = "Data Set Name: ")
# Assign variable
dataset_name_var1 <- dataset_name_df_var1[1,1]
# View variable name
dataset_name_var1## [1] "aaaq.sas7bdat"Now that we have the dataset name stored as a variable, we can create a dataframe that will correspond to the rows in our variables dataframe. The challenge is that each dataset contains a different number of variables! We can determine how many rows each dataset contains by returning to our variables dataframe and calculating the number of rows associated with each dataset. The following code splits the variables dataframe into a list of dataframes by each occurrence of 1 in the “Num” column (when the numbering restarts for a new dataset).
# Calculate the number of rows associated with each dataset for reference
dataset_list <- split(variables, cumsum(variables$Num == 1))
glimpse(dataset_list[1:3])## List of 3
## $ 1:'data.frame': 13 obs. of 4 variables:
## ..$ Num : num [1:13] 1 2 3 4 5 6 7 8 9 10 ...
## ..$ Variable: chr [1:13] "AAQ_1000" "AAQ_1010" "AAQ_1020" "AAQ_1030" ...
## ..$ Type : chr [1:13] "Num" "Num" "Num" "Num" ...
## ..$ Label : chr [1:13] "In the past 3 days, how much of the time did your asthma keep you from doing your usual activities at work, sch"| __truncated__ "During the past 3 days, how often have you had asthma symptoms? 0=Not at all, 1=Once per day, 2=2-3 times per d"| __truncated__ "During the past 3 days, how often have you used your rescue inhaler or nebulizer medication ? 0=Not at all, 1=O"| __truncated__ "During the past 3 days, how many total times did your asthma symptoms wake you up from sleep? 0=Not at all, 1=1"| __truncated__ ...
## $ 2:'data.frame': 30 obs. of 4 variables:
## ..$ Num : num [1:30] 1 2 3 4 5 6 7 8 9 10 ...
## ..$ Variable: chr [1:30] "ABP_1000" "ABP_1010" "ABP_1020" "ABP_1030" ...
## ..$ Type : chr [1:30] "Num" "Num" "Num" "Num" ...
## ..$ Label : chr [1:30] "Are you currently retired? 1=Yes,0=No" "Are you retired because of asthma? 1=Yes,0=No" "Are you currently unemployed? 1=Yes,0=No" "Are you unemployed because of asthma? 1=Yes,0=No" ...
## $ 3:'data.frame': 11 obs. of 4 variables:
## ..$ Num : num [1:11] 1 2 3 4 5 6 7 8 9 10 ...
## ..$ Variable: chr [1:11] "ACT_1" "ACT_2" "ACT_3" "ACT_4" ...
## ..$ Type : chr [1:11] "Num" "Num" "Num" "Num" ...
## ..$ Label : chr [1:11] "In the past 4 weeks, how much of the time did your asthma keep you from getting as much done at work, school or"| __truncated__ "During the past 4 weeks, how often have your had shortness of breath? 1=All of the time, 2=Most of the time, 3="| __truncated__ "During the past 4 weeks, how often did your asthma symptoms wake you up at night or earlier than usual in the m"| __truncated__ "During the past 4 weeks, how often have you used your rescue inhaler or nebulizer medication? 1=All of the time"| __truncated__ ...The number of rows in each list is the number of variables in that dataset. We can use this value in creating our dataframe of dataset names.
# Store the number of rows in a variable
n_rows = nrow(data.frame(dataset_list[1]))
# Repeat the dataset name for the number of variables there are
dataset_name_var1 = data.frame("dataset_name" = rep(dataset_name_var1, times = n_rows))
# View data farme
datatable(dataset_name_var1)We now have a dataframe that can be joined with our variables dataframe for the first table. We can apply this approach to each table in our original PDF using a for loop.
# Make dataframe to store dataset names
dataset_names <- data.frame()
# Create list of datasets
dataset_list <- split(variables, cumsum(variables$Num == 1))
# Remove elements from the table_names vector that do not contain the string "Data Set Name"
table_names_filtered <- stringr::str_subset(table_names, 'Data Set Name')
# Populate dataset_names dataframe
for (i in 1:length(table_names_filtered)) {
# Get dataset name
dataset_name_df <- data.frame(strsplit(table_names_filtered[i], "\n"))
base::colnames(dataset_name_df) <- c("Text")
dataset_name_df <- dataset_name_df %>%
filter(grepl("Data Set Name", dataset_name_df$Text)) %>%
separate(Text, into = c(NA, "dataset"), sep = "Data Set Name: ")
dataset_name <- dataset_name_df[1,1]
# Determine number of variables in that dataset
data_set <- data.frame(dataset_list[i])
n_rows = nrow(data_set)
# Repeat the dataset name for the number of variables there are
dataset_name = data.frame("Data Set Name" = rep(dataset_name, times = n_rows))
# Bind to dataframe
dataset_names <- bind_rows(dataset_names, dataset_name)
}
# Rename column
colnames(dataset_names) <- c("Data Set Name")
# View
datatable(dataset_names)Combining Dataset Names and Variable Information
Last, we will merge together the dataframe containing dataset names and variable information.
# Merge together
final_variable_df <- cbind(dataset_names, variables) %>%
rename("Variable Description" = "Label", "Variable Number Within Dataset" = "Num") %>%
clean_names()
datatable(final_variable_df)We can also determine how many total variables we have, all of which are accessible via the table we just generated.
## [1] 1190With this, we can answer Environmental Health Question #2: How many variables total are available to us to request from the study whose data are stored in the repository, and what are these variables?
Answer: There are 1190 variable available to us. We can browse through the variables, including the sub-table they were from, the type of variable they are, and how they were derived using the table we generated.
Concluding Remarks
This training module provides example case studies demonstrating how to import PDF data into R and clean it so that it is more useful and accessible for analyses. The approaches demonstrated in this module, though specific to our specific example data, can be adapted to many different types of PDF data.
Using the same input files that we used in part 1, “Importing Data from Many Single PDFs with the Same Formatting”, found in the Module4_3_TYKInput folder, extract the remaining variables of interest (Original Concentration and Positions Removed) from the PDFs and summarize them in one dataframe.