3.2 Gene Expression Omnibus
This training module was developed by Dr. Kyle R. Roell and Dr. Julia E. Rager
Fall 2021
Important update: we released an updated version of TAME, called TAME 2.0, now publicly available at: Tame 2.0
Introduction to the Environmental Health Database, Gene Expression Omnibus (GEO)
GEO is a publicly available database repository of high-throughput gene expression data and hybridization arrays, chips, and microarrays that span genome-wide endpoints of genomics, transcriptomics, and epigenomics. The repository is organized and managed by the The National Center for Biotechnology Information (NCBI), which seeks to advance science and health by providing access to biomedical and genomic information. The three overall goals of GEO are to: (1) Provide a robust, versatile database in which to efficiently store high-throughput functional genomic data, (2) Offer simple submission procedures and formats that support complete and well-annotated data deposits from the research community, and (3) Provide user-friendly mechanisms that allow users to query, locate, review and download studies and gene expression profiles of interest.
Of high relevance to environmental health, data organized within GEO can be pulled and analyzed to address new environmental health questions, leveraging previously generated data. For example, we have pulled gene expression data from acute myeloid leukemia patients and re-analyzed these data to elucidate new mechanisms of epigenetically-regulated networks involved in cancer, that in turn, may be modified by environmental insults, as previously published in Rager et al. 2012. We have also pulled and analyzed gene expression data from published studies evaluating toxicity resulting from hexavalent chromium exposure, to further substantiate the role of epigenetic mediators in hexavelent chromium-induced carcinogenesis (see Rager et al. 2019). This training exercise leverages an additional dataset that we published and deposited through GEO to evaluate the effects of formaldehyde inhalation exposure, as detailed below.
Introduction to Training Module
This training module provides an overview on pulling and analyzing data deposited in GEO. As an example, data are pulled from the published GEO dataset recorded through the online series GSE42394. This series represents Affymetrix rat genome-wide microarray data generated from our previous study, aimed at evaluating the transcriptomic effects of formaldehyde across three tissues: the nose, blood, and bone marrow. For the purposes of this training module, we will focus on evaluating gene expression profiles from nasal samples after 7 days of exposure, collected from rats exposed to 2 ppm formaldehyde via inhalation. These findings, in addition to other epigenomic endpoint measures, have been previously published (see Rager et al. 2014).
This training module specifically guides trainees through the loading of required packages and data, including the manual upload of GEO data as well as the upload/organization of data leveraging the GEOquery package. Data are then further organized and combined with gene annotation information through the merging of platform annotation files. Example visualizations are then produced, including boxplots to evaluate the overall distribution of expression data across samples, as well as heat map visualizations that compare unscaled versus scaled gene expression values. Statistical analyses are then included to identify which genes are significantly altered in expression upon exposure to formaldehyde. Together, this training module serves as a simple example showing methods to access and download GEO data and to perform data organization, analysis, and visualization tasks through applications-based questions.
Training Module’s Environmental Health Questions
This training module was specifically developed to answer the following environmental health questions:
- What kind of molecular identifiers are commonly used in microarray-based -omics technologies?
- How can we convert platform-specific molecular identifiers used in -omics study designs to gene-level information?
- Why do we often scale gene expression signatures prior to heat map visualizations?
- What genes are altered in expression by formaldehyde inhalation exposure?
- What are the potential biological consequences of these gene-level perturbations?
Installing required R packages
If you already have these packages installed, you can skip this step, or you can run the below code which checks installation status for you
if (!requireNamespace("tidyverse"))
install.packages("tidyverse")
if (!requireNamespace("reshape2"))
install.packages("reshape2")
# GEOquery, this will install BiocManager if you don't have it installed
if (!requireNamespace("BiocManager"))
install.packages("BiocManager")
BiocManager::install("GEOquery")## Warning: package(s) not installed when version(s) same as current; use `force = TRUE` to
## re-install: 'GEOquery'Loading R packages required for this session
library(tidyverse)
library(reshape2)
library(GEOquery)For more information on the tidyverse package, see its associated CRAN webpage, primary webpage, and peer-reviewed article released in 2018.
For more information on the reshape2 package, see its associated CRAN webpage, R Documentation, and helpful website providing an introduction to the reshape2 package.
For more information on the GEOquery package, see its associated Bioconductor website and R Documentation file.
Loading and Organizing the Example Dataset
Let’s start by loading the GEO dataset needed for this training module. As explained in the introduction, this module walks through two methods of uploading GEO data: manual option vs automatic option using the GEOquery package. These two methods are detailed below.
GEO Data in R
1. Manually Downloading and Uploading GEO Files
In this first method, we will navigate to the datasets within the GEO website, manually download its associated text data file, save it in our working directory, and then upload it into our global environment in R.
For the purposes of this training exercise, we manually downloaded the GEO series matrix file from the GEO series webpage, located at: https://www.ncbi.nlm.nih.gov/geo/query/acc.cgi?acc=GSE42394. The specific file that was downloaded was noted as GSE42394_series_matrix.txt, pulled by clicking on the link indicated by the red arrow from the GEO series webpage:

For simplicity, we also have already pre-filtered this file for the samples we are interested in, focusing on the rat nasal gene expression data after 7 days of exposure to gaseous formaldehyde. This filtered file was saved as: GSE42394_series_matrix_filtered.txt
At this point, we can simply read in this pre-filtered text file for the purposes of this training module
geodata_manual = read.table(file="Module3_2/Module3_2_GSE42394_series_matrix_filtered.txt",
header=T)Because this is a manual approach, we have to also manually define the treated and untreated samples (based on manually opening the surrounding metadata from the GEO webpage)
Manually defining treated and untreated for these samples of interest:
exposed_manual = c("GSM1150940", "GSM1150941", "GSM1150942")
unexposed_manual = c("GSM1150937", "GSM1150938", "GSM1150939")2. Uploading and Organizing GEO Files through the GEOquery Package
In this second method, we will leverage the GEOquery package, which allows for easier downloading and reading in of data from GEO without having to manually download raw text files, and manually assign sample attributes (e.g., exposed vs unexposed). This package is set-up to automatically merge sample information from GEO metadata files with raw genome-wide datasets.
Let’s first use the getGEO function (from the GEOquery package) to load data from our series matrix. Note that this line of code may take a couple of minutes
geo.getGEO.data = getGEO(filename='Module3_2/Module3_2_GSE42394_series_matrix.txt')One of the reasons the getGEO package is so helpful is that we can automatically link a dataset with nicely organized sample information using the pData() function.
sampleInfo = pData(geo.getGEO.data)Let’s view this sample information / metadata file, first by viewing what the column headers are.
colnames(sampleInfo)## [1] "title" "geo_accession"
## [3] "status" "submission_date"
## [5] "last_update_date" "type"
## [7] "channel_count" "source_name_ch1"
## [9] "organism_ch1" "characteristics_ch1"
## [11] "characteristics_ch1.1" "characteristics_ch1.2"
## [13] "characteristics_ch1.3" "characteristics_ch1.4"
## [15] "characteristics_ch1.5" "treatment_protocol_ch1"
## [17] "growth_protocol_ch1" "molecule_ch1"
## [19] "extract_protocol_ch1" "label_ch1"
## [21] "label_protocol_ch1" "taxid_ch1"
## [23] "hyb_protocol" "scan_protocol"
## [25] "description" "data_processing"
## [27] "platform_id" "contact_name"
## [29] "contact_email" "contact_department"
## [31] "contact_institute" "contact_address"
## [33] "contact_city" "contact_zip/postal_code"
## [35] "contact_country" "supplementary_file"
## [37] "data_row_count" "age:ch1"
## [39] "cell type:ch1" "gender:ch1"
## [41] "strain:ch1" "time:ch1"
## [43] "treatment:ch1"Then viewing the first five columns.
sampleInfo[1:10,1:5]## title geo_accession
## GSM1150937 Nose_7DayControl_Rep1 [Affymetrix] GSM1150937
## GSM1150938 Nose_7DayControl_Rep2 [Affymetrix] GSM1150938
## GSM1150939 Nose_7DayControl_Rep3 [Affymetrix] GSM1150939
## GSM1150940 Nose_7DayExposed_Rep1 [Affymetrix] GSM1150940
## GSM1150941 Nose_7DayExposed_Rep2 [Affymetrix] GSM1150941
## GSM1150942 Nose_7DayExposed_Rep3 [Affymetrix] GSM1150942
## GSM1150943 WhiteBloodCells_7DayControl_Rep1 [Affymetrix] GSM1150943
## GSM1150944 WhiteBloodCells_7DayControl_Rep2 [Affymetrix] GSM1150944
## GSM1150945 WhiteBloodCells_7DayControl_Rep3 [Affymetrix] GSM1150945
## GSM1150946 WhiteBloodCells_7DayExposed_Rep1 [Affymetrix] GSM1150946
## status submission_date last_update_date
## GSM1150937 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150938 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150939 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150940 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150941 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150942 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150943 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150944 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150945 Public on Jan 07 2014 May 29 2013 Jan 07 2014
## GSM1150946 Public on Jan 07 2014 May 29 2013 Jan 07 2014This shows that each sample is provided with a unique number starting with “GSM”, and these are described by information summarized in the “title” column. We can also see that these data were made public on Jan 7, 2014.
Let’s view the next five columns.
sampleInfo[1:10,6:10]## type channel_count source_name_ch1
## GSM1150937 RNA 1 Nasal epithelial cells, 7 day, unexposed
## GSM1150938 RNA 1 Nasal epithelial cells, 7 day, unexposed
## GSM1150939 RNA 1 Nasal epithelial cells, 7 day, unexposed
## GSM1150940 RNA 1 Nasal epithelial cells, 7 day, exposed
## GSM1150941 RNA 1 Nasal epithelial cells, 7 day, exposed
## GSM1150942 RNA 1 Nasal epithelial cells, 7 day, exposed
## GSM1150943 RNA 1 Circulating white blood cells, 7 day, unexposed
## GSM1150944 RNA 1 Circulating white blood cells, 7 day, unexposed
## GSM1150945 RNA 1 Circulating white blood cells, 7 day, unexposed
## GSM1150946 RNA 1 Circulating white blood cells, 7 day, exposed
## organism_ch1 characteristics_ch1
## GSM1150937 Rattus norvegicus gender: male
## GSM1150938 Rattus norvegicus gender: male
## GSM1150939 Rattus norvegicus gender: male
## GSM1150940 Rattus norvegicus gender: male
## GSM1150941 Rattus norvegicus gender: male
## GSM1150942 Rattus norvegicus gender: male
## GSM1150943 Rattus norvegicus gender: male
## GSM1150944 Rattus norvegicus gender: male
## GSM1150945 Rattus norvegicus gender: male
## GSM1150946 Rattus norvegicus gender: maleWe can see that information is provided here surrounding the type of sample that was analyzed (i.e., RNA), more information on the collected samples within the column ‘source_name_ch1’, and the organism (rat) is provided in the ‘organism_ch1’ column.
More detailed metadata information is provided throughout this file, as seen when viewing the column headers above.
Defining Samples
Now, we can use this information to define the samples we want to analyze. Note that this is the same step we did manually above.
In this training exercise, we are focusing on responses in the nose, so we can easily filter for cell type = Nasal epithelial cells (specifically in the “cell type:ch1” variable). We are also focusing on responses collected after 7 days of exposure, which we can filter for using time = 7 day (specifically in the “time:ch1” variable). We will also define exposed and unexposed samples using the variable “treatment:ch1”.
First, let’s subset the sampleInfo dataframe to just keep the samples we’re interested in
# Define a vector variable (here we call it 'keep') that will store rows we want to keep
keep = rownames(sampleInfo[which(sampleInfo$`cell type:ch1`=="Nasal epithelial cells"
& sampleInfo$`time:ch1`=="7 day"),])
# Then subset the sample info for just those samples we defined in keep variable
sampleInfo = sampleInfo[keep,]Next, we can pull the exposed and unexposed animal IDs. Let’s first see how these are labeled within the “treatment:ch1” variable.
unique(sampleInfo$`treatment:ch1`)## [1] "unexposed" "2 ppm formaldehyde"And then search for the rows of data, pulling the sample animal IDs (which are in the variable ‘geo_accession’).
exposedIDs = sampleInfo[which(sampleInfo$`treatment:ch1`=="2 ppm formaldehyde"),
"geo_accession"]
unexposedIDs = sampleInfo[which(sampleInfo$`treatment:ch1`=="unexposed"),
"geo_accession"]The next step is to pull the expression data we want to use in our analyses. The GEOquery function, exprs(), allows us to easily pull these data. Here, we can pull the data we’re interested in using the exprs() function, while defining the data we want to pull based off our previously generated ‘keep’ vector.
# As a reminder, this is what the 'keep' vector includes
# (i.e., animal IDs that we're interested in)
keep## [1] "GSM1150937" "GSM1150938" "GSM1150939" "GSM1150940" "GSM1150941"
## [6] "GSM1150942"# Using the exprs() function
geodata = exprs(geo.getGEO.data[,keep])Let’s view the full dataset as is now:
head(geodata)## GSM1150937 GSM1150938 GSM1150939 GSM1150940 GSM1150941 GSM1150942
## 10700001 5786.60 5830.08 5637.34 5313.33 5557.04 5469.90
## 10700002 192.92 206.86 220.83 183.12 177.16 198.64
## 10700003 1820.98 1795.79 1735.70 1578.02 1681.58 1632.20
## 10700004 66.95 65.61 64.41 60.19 60.41 60.67
## 10700005 770.07 753.41 731.20 684.53 657.25 667.66
## 10700006 5.80 5.35 5.48 5.58 5.39 5.35This now represents a matrix of data, with animal IDs as column headers and expression levels within the matrix.
Simplifying column names
These column names are not the easiest to interpret, so let’s rename these columns to indicate which animals were from the exposed vs. unexposed groups.
We need to first convert our expression dataset to a dataframe so we can edit columns names, and continue with downstream data manipulations that require dataframe formats.
geodata = data.frame(geodata)Let’s remind ourselves what the column names are:
colnames(geodata)## [1] "GSM1150937" "GSM1150938" "GSM1150939" "GSM1150940" "GSM1150941"
## [6] "GSM1150942"Which ones of these are exposed vs unexposed animals can be determined by viewing our previously defined vectors.
exposedIDs## [1] "GSM1150940" "GSM1150941" "GSM1150942"unexposedIDs## [1] "GSM1150937" "GSM1150938" "GSM1150939"With this we can tell that the first three listed IDs are from unexposed animals, and the last three IDs are from exposed animals.
Let’s simplify the names of these columns to indicate exposure status and replicate number.
colnames(geodata) = c("Control_1", "Control_2", "Control_3", "Exposed_1",
"Exposed_2", "Exposed_3")And we’ll now need to re-define our ‘exposed’ vs ‘unexposed’ vectors for downstream script.
exposedIDs = c("Exposed_1", "Exposed_2", "Exposed_3")
unexposedIDs = c("Control_1", "Control_2", "Control_3")Viewing the data again:
head(geodata)## Control_1 Control_2 Control_3 Exposed_1 Exposed_2 Exposed_3
## 10700001 5786.60 5830.08 5637.34 5313.33 5557.04 5469.90
## 10700002 192.92 206.86 220.83 183.12 177.16 198.64
## 10700003 1820.98 1795.79 1735.70 1578.02 1681.58 1632.20
## 10700004 66.95 65.61 64.41 60.19 60.41 60.67
## 10700005 770.07 753.41 731.20 684.53 657.25 667.66
## 10700006 5.80 5.35 5.48 5.58 5.39 5.35These data are now looking easier to interpret/analyze. Still, the row identifiers include 8 digit numbers starting with “107…”. We know that this dataset is a gene expression dataset, but these identifiers, in themselves, don’t tell us much about what genes these are referring to. These numeric IDs specifically represent microarray probesetIDs, that were produced by the Affymetrix platform used in the original study.
But how can we tell which genes are represented by these data?!
Adding Gene Symbol Information
Each -omics dataset contained within GEO points to a specific platform that was used to obtain measurements. In instances where we want more information surrounding the molecular identifiers, we can merge the platform-specific annotation file with the molecular IDs given in the full dataset.
For example, let’s pull the platform-specific annotation file for this experiment.
- Let’s revisit the website that contained the original dataset on GEO
- Scroll down to where it lists “Platforms”, and there is a hyperlinked platform number “GPL6247” (see arrow below)
- Click on this, and you will be navigated to a different GEO website describing the Affymetrix rat array platform that was used in this analysis
- Note that this website also includes information on when this array became available, links to other experiments that have used this platform within GEO, and much more
- Here, we’re interested in pulling the corresponding gene symbol information for the probeset IDs
- To do so, scroll to the bottom, and click “Annotation SOFT table…” and download the corresponding .gz file within your working directory
- Unzip this, and you will find the master annotation file: “GPL6247.annot”
In this exercise, we’ve already done these steps and unzipped the file in our working directory. So at this point, we can simply read in this annotation dataset, still using the GEOquery function to help automate.
geo.annot = GEOquery::getGEO(filename="Module3_2/Module3_2_GPL6247.annot")Now we can use the Table function from GEOquery to pull data from the annotation dataset.
id.gene.table = GEOquery::Table(geo.annot)[,c("ID", "Gene symbol")]
id.gene.table[1:10,1:2]## ID Gene symbol
## 1 10701620 Vom2r67///Vom2r5///Vom2r6///Vom2r4
## 2 10701630
## 3 10701632
## 4 10701636
## 5 10701643
## 6 10701648 Vom2r5
## 7 10701654 Vom2r6
## 8 10701663
## 9 10701666
## 10 10701668 Vom2r65///Vom2r1With these two columns of data, we now have the needed IDs and gene symbols to match with our dataset.
Within the full dataset, we need to add a new column for the probeset ID, taken from the rownames, in preparation for the merging step.
geodata$ID = rownames(geodata)We can now merge the gene symbol information by ID with our expression data.
geodata_genes = merge(geodata, id.gene.table, by="ID")
head(geodata_genes)## ID Control_1 Control_2 Control_3 Exposed_1 Exposed_2 Exposed_3
## 1 10700001 5786.60 5830.08 5637.34 5313.33 5557.04 5469.90
## 2 10700002 192.92 206.86 220.83 183.12 177.16 198.64
## 3 10700003 1820.98 1795.79 1735.70 1578.02 1681.58 1632.20
## 4 10700004 66.95 65.61 64.41 60.19 60.41 60.67
## 5 10700005 770.07 753.41 731.20 684.53 657.25 667.66
## 6 10700006 5.80 5.35 5.48 5.58 5.39 5.35
## Gene symbol
## 1
## 2
## 3
## 4
## 5
## 6Note that many of the probeset IDs do not map to full gene symbols, which is shown here by viewing the top few rows - this is expected in genome-wide analyses based on microarray platforms.
Let’s look at the first 25 unique genes in these data:
UniqueGenes = unique(geodata_genes$`Gene symbol`)
UniqueGenes[1:25]## [1] ""
## [2] "Vom2r67///Vom2r5///Vom2r6///Vom2r4"
## [3] "Vom2r5"
## [4] "Vom2r6"
## [5] "Vom2r65///Vom2r1"
## [6] "Vom2r65///Vom2r5///Vom2r1///Vom2r6///Vom2r4"
## [7] "Vom2r65///Vom2r5///Vom2r6///Vom2r4"
## [8] "Raet1e"
## [9] "Lrp11"
## [10] "Katna1"
## [11] "Ppil4"
## [12] "Zc3h12d"
## [13] "Shprh"
## [14] "Fbxo30"
## [15] "Epm2a"
## [16] "Sf3b5"
## [17] "Plagl1"
## [18] "Fuca2"
## [19] "Adat2"
## [20] "Hivep2"
## [21] "Nmbr"
## [22] "Cited2"
## [23] "Txlnb"
## [24] "Reps1"
## [25] "Perp"Again, you can see that the first value listed is blank, representing probesetIDs that do not match to fully annotated gene symbols. Though the rest pertain for gene symbols annotated to the rat genome.
You can also see that some gene symbols have multiple entries, separated by “///”
To simplify identifiers, we can pull just the first gene symbol, and remove the rest by using gsub().
geodata_genes$`Gene symbol` = gsub("///.*", "", geodata_genes$`Gene symbol`)Let’s alphabetize by main expression dataframe by gene symbol.
geodata_genes = geodata_genes[order(geodata_genes$`Gene symbol`),]And then re-view these data:
geodata_genes[1:5,]## ID Control_1 Control_2 Control_3 Exposed_1 Exposed_2 Exposed_3
## 1 10700001 5786.60 5830.08 5637.34 5313.33 5557.04 5469.90
## 2 10700002 192.92 206.86 220.83 183.12 177.16 198.64
## 3 10700003 1820.98 1795.79 1735.70 1578.02 1681.58 1632.20
## 4 10700004 66.95 65.61 64.41 60.19 60.41 60.67
## 5 10700005 770.07 753.41 731.20 684.53 657.25 667.66
## Gene symbol
## 1
## 2
## 3
## 4
## 5In preparation for the visualization steps below, let’s reset the probeset IDs to rownames.
rownames(geodata_genes) = geodata_genes$ID
# Can then remove this column within the dataframe
geodata_genes$ID = NULLFinally let’s rearrange this dataset to include gene symbols as the first column, right after rownames (probeset IDs).
geodata_genes = geodata_genes[,c(ncol(geodata_genes),1:(ncol(geodata_genes)-1))]
geodata_genes[1:5,]## Gene symbol Control_1 Control_2 Control_3 Exposed_1 Exposed_2
## 10700001 5786.60 5830.08 5637.34 5313.33 5557.04
## 10700002 192.92 206.86 220.83 183.12 177.16
## 10700003 1820.98 1795.79 1735.70 1578.02 1681.58
## 10700004 66.95 65.61 64.41 60.19 60.41
## 10700005 770.07 753.41 731.20 684.53 657.25
## Exposed_3
## 10700001 5469.90
## 10700002 198.64
## 10700003 1632.20
## 10700004 60.67
## 10700005 667.66dim(geodata_genes)## [1] 29214 7Note that this dataset includes expression measures across 29,214 probes, representing 14,019 unique genes. For simplicity in the final exercises, let’s just filter for rows representing mapped genes.
geodata_genes = geodata_genes[!(geodata_genes$`Gene symbol` == ""), ]
dim(geodata_genes)## [1] 16024 7Note that this dataset now includes 16,024 rows with mapped gene symbol identifiers.
With this, we can now answer Environmental Health Question 1: What kind of molecular identifiers are commonly used in microarray-based -omics technologies?
Answer: Platform-specific probeset IDs.
We can also answer Environmental Health Question 2: How can we convert platform-specific molecular identifiers used in -omics study designs to gene-level information?
Answer: We can merge platform-specific IDs with gene-level information using annotation files.
Visualizing Data
Visualizing Gene Expression Data using Boxplots and Heat Maps
- To visualize the -omics data, we can generate boxplots, heat maps, any many other types of visualizations
- Here, we provide an example to plot a boxplot, which can be used to visualize the variability amongst samples
- We also provide an example to plot a heat map, comparing unscaled vs scaled gene expression profiles
- These visualizations can be useful to both simply visualize the data as well as identify patterns across samples or genes
Boxplot Visualizations
For this example, let’s simply use R’s built in boxplot() function.
We only want to use columns with our expression data (2 to 7), so let’s pull those columns when running the boxplot function.
boxplot(geodata_genes[,2:7])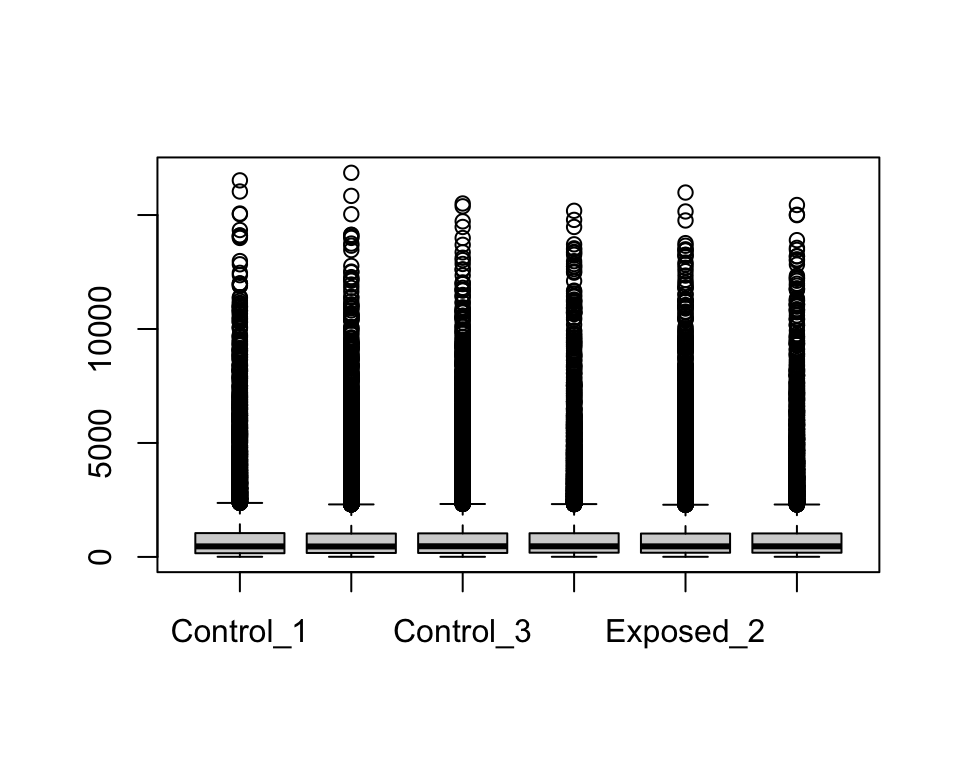
There seem to be a lot of variability within each sample’s range of expression levels, with many outliers. This makes sense given that we are analyzing the expression levels across the rat’s entire genome, where some genes won’t be expressed at all while others will be highly expressed due to biological and/or potential technical variability.
To show plots without outliers, we can simply use outline=F.
boxplot(geodata_genes[,2:7], outline=F)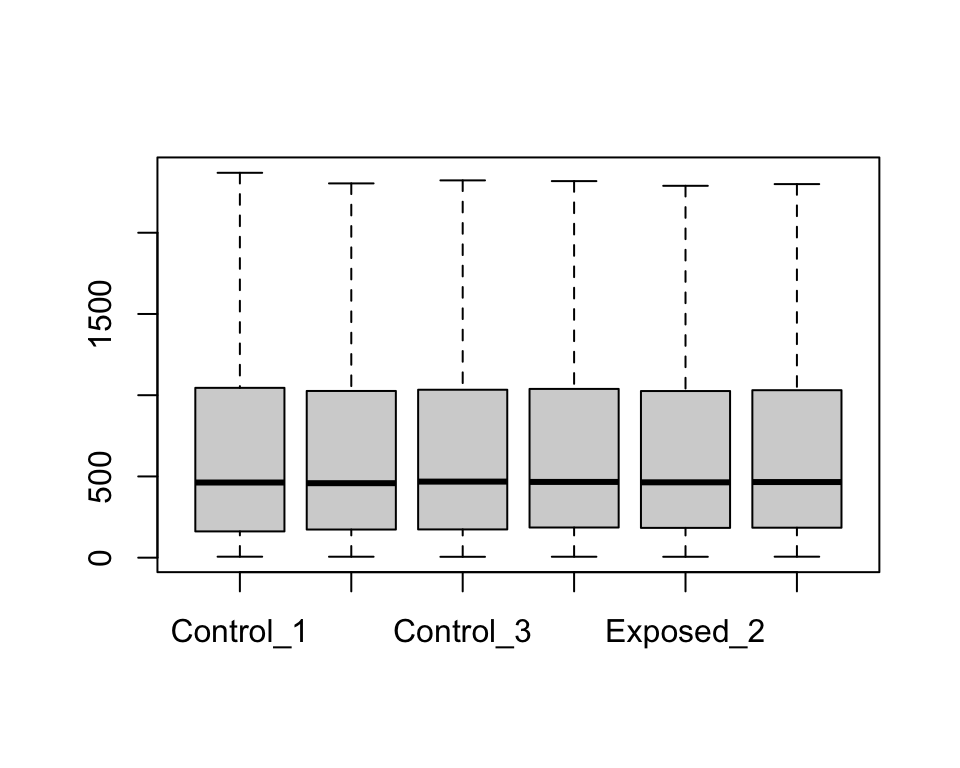
Heat Map Visualizations
Heat maps are also useful when evaluating large datasets.
There are many different packages you can use to generate heat maps. Here, we use the superheat package.
It also takes awhile to plot all genes across the genome, so to save time for this training module, let’s randomly select 100 rows to plot.
# To ensure that the same subset of genes are selected each time
set.seed = 101
# Random selection of 100 rows
row.sample = sample(1:nrow(geodata_genes),100)
# Heat map code
superheat::superheat(geodata_genes[row.sample,2:7], # Only want to plot non-id/gene symbol columns (2 to 7)
pretty.order.rows = TRUE,
pretty.order.cols = TRUE,
col.dendrogram = T,
row.dendrogram = T)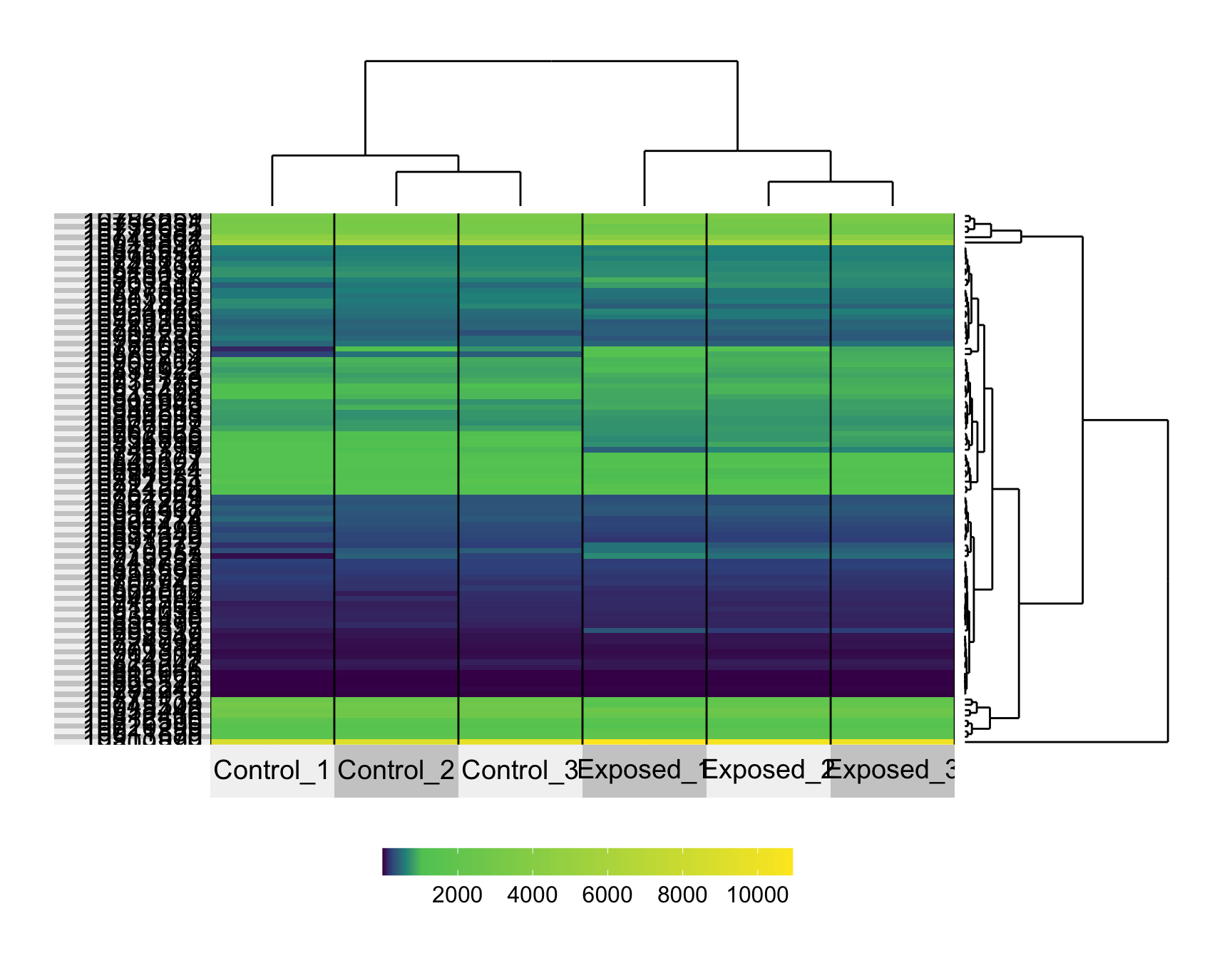
This produces a heat map with sample IDs along the x-axis and probeset IDs along the y-axis. Here, the values being displayed represent normalized expression values.
One way to improve our ability to distinguish differences between samples is to scale expression values across probes.
Scaling data
Z-score is a very common method of scaling that transforms data points to reflect the number of standard deviations they are from the overall mean. Z-score scaling data results in the overall transformation of a dataset to have an overall mean = 0 and standard deviation = 1.
Let’s see what happens when we scale this gene expression dataset by z-score across each probe. This can be easily done using the scale function.
This specific scale function works by centering and scaling across columns, but since we want to use it across probesets (organized as rows), we need to first transpose our dataset, then run the scale function.
geodata_genes_scaled = scale(t(geodata_genes[,2:7]), center=T, scale=T)Now we can transpose it back to the original format (i.e., before it was transposed).
geodata_genes_scaled = t(geodata_genes_scaled)And then view what the normalized and now scaled expression data look like for now a random subset of 100 probesets (representing genes).
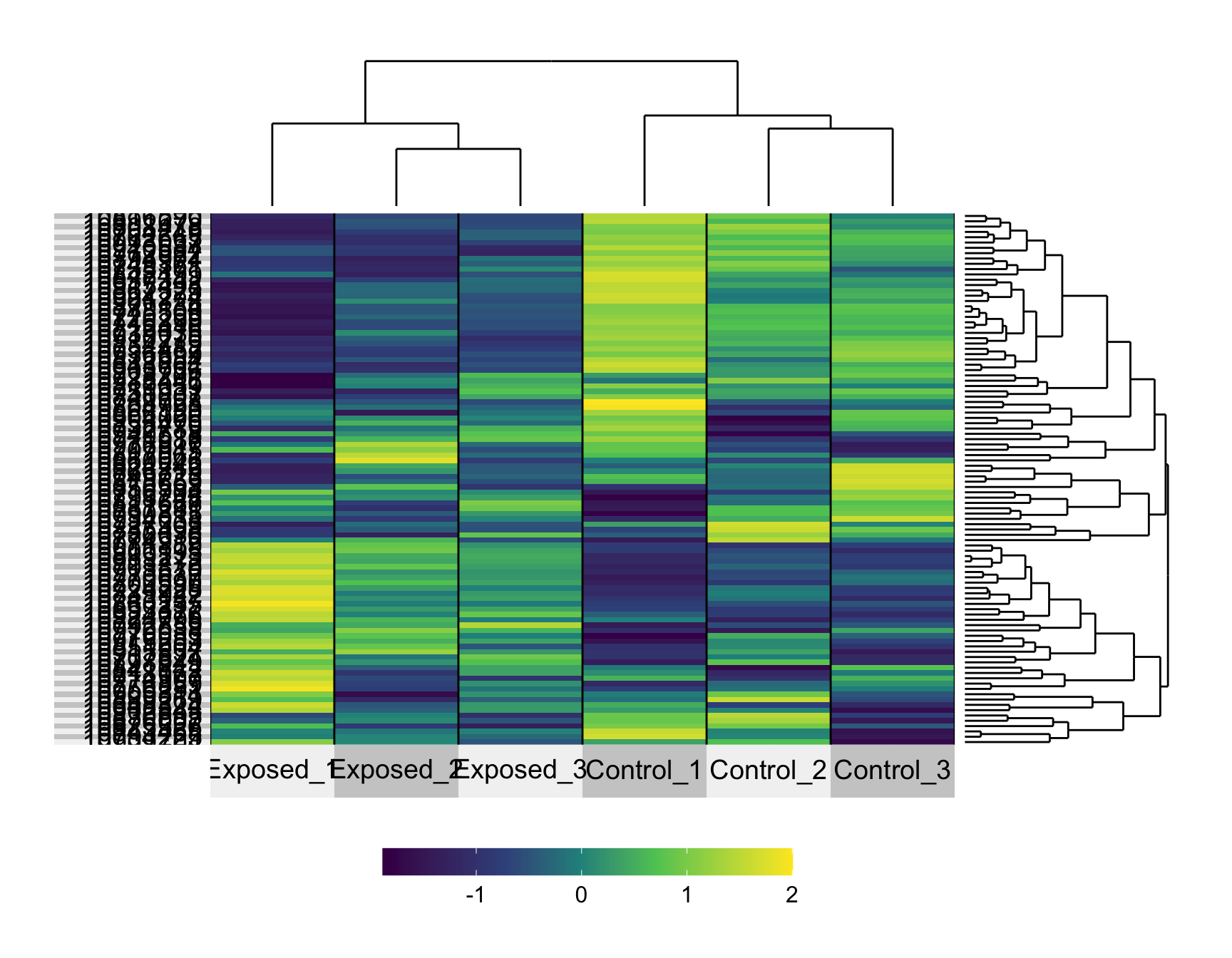
With these data now scaled, we can more easily visualize patterns between samples.
We can also answer Environmental Health Question 3: Why do we often scale gene expression signatures prior to heat map visualizations?
Answer: To better visualize patterns in expression signatures between samples.
Now, with these data nicely organized, we can see how statistics can help find which genes show trends in expression associated with formaldehyde exposure.
Statistical Analyses
Statistical Analyses to Identify Genes altered by Formaldehyde
A simple way to identify differences between formaldehyde-exposed and unexposed samples is to use a t-test. Because there are so many tests being performed, one for each gene, it is also important to carry out multiple test corrections through a p-value adjustment method.
We need to run a t-test for each row of our dataset. This exercise demonstrates two different methods to run a t-test:
- Method 1: using a ‘for loop’
- Method 2: using the apply function (more computationally efficient)
Method 1 (m1): ‘For Loop’
Let’s first re-save the molecular probe IDs to a column within the dataframe, since we need those values in the loop function.
geodata_genes$ID = rownames(geodata_genes)We also need to initially create an empty dataframe to eventually store p-values.
pValue_m1 = matrix(0, nrow=nrow(geodata_genes), ncol=3)
colnames(pValue_m1) = c("ID", "pval", "padj")
head(pValue_m1)## ID pval padj
## [1,] 0 0 0
## [2,] 0 0 0
## [3,] 0 0 0
## [4,] 0 0 0
## [5,] 0 0 0
## [6,] 0 0 0You can see the empty dataframe that was generated through this code.
Then we can loop through the entire dataset to acquire p-values from t-test statistics, comparing n=3 exposed vs n=3 unexposed samples.
for (i in 1:nrow(geodata_genes)) {
#Get the ID
ID.i = geodata_genes[i, "ID"];
#Run the t-test and get the p-value
pval.i = t.test(geodata_genes[i,exposedIDs], geodata_genes[i,unexposedIDs])$p.value;
#Store the data in the empty dataframe
pValue_m1[i,"ID"] = ID.i;
pValue_m1[i,"pval"] = pval.i
}View the results:
# Note that we're not pulling the last column (padj) since we haven't calculated these yet
pValue_m1[1:5,1:2] ## ID pval
## [1,] "10903987" "0.0812802229304083"
## [2,] "10714794" "0.757311314118124"
## [3,] "10858408" "0.390952310869689"
## [4,] "10872252" "0.0548937136005506"
## [5,] "10905819" "0.173539535577791"Method 2 (m2): Apply Function
For the second method, we can use the apply() function to calculate resulting t-test p-values more efficiently labeled.
pValue_m2 = apply(geodata_genes[,2:7], 1, function(x) t.test(x[unexposedIDs],
x[exposedIDs])$p.value)
names(pValue_m2) = geodata_genes[,"ID"]We can convert the results into a dataframe to make it similar to m1 matrix we created above.
pValue_m2 = data.frame(pValue_m2)
# Now create an ID column
pValue_m2$ID = rownames(pValue_m2)Then we can view at the two datasets to see they result in the same pvalues.
head(pValue_m1)## ID pval padj
## [1,] "10903987" "0.0812802229304083" "0"
## [2,] "10714794" "0.757311314118124" "0"
## [3,] "10858408" "0.390952310869689" "0"
## [4,] "10872252" "0.0548937136005506" "0"
## [5,] "10905819" "0.173539535577791" "0"
## [6,] "10907585" "0.215200167867295" "0"head(pValue_m2)## pValue_m2 ID
## 10903987 0.08128022 10903987
## 10714794 0.75731131 10714794
## 10858408 0.39095231 10858408
## 10872252 0.05489371 10872252
## 10905819 0.17353954 10905819
## 10907585 0.21520017 10907585We can see from these results that both methods (m1 and m2) generate the same statistical p-values.
Interpreting Results
Let’s again merge these data with the gene symbols to tell which genes are significant.
First, let’s convert to a dataframe and then merge as before, for one of the above methods as an example (m1).
pValue_m1 = data.frame(pValue_m1)
pValue_m1 = merge(pValue_m1, id.gene.table, by="ID")We can also add a multiple test correction by applying a false discovery rate-adjusted p-value; here, using the Benjamini Hochberg (BH) method.
# Here fdr is an alias for B-H method
pValue_m1[,"padj"] = p.adjust(pValue_m1[,"pval"], method=c("fdr"))Now, we can sort these statistical results by adjusted p-values.
pValue_m1.sorted = pValue_m1[order(pValue_m1[,'padj']),]
head(pValue_m1.sorted)## ID pval padj Gene symbol
## 9143 10837582 4.57288413593085e-07 0.00732759 Olr633
## 5640 10783648 1.93688668590855e-06 0.01551834 Slc7a8
## 8 10701699 0.0166773380386967 0.13089115 Lrp11
## 17 10701817 0.0131845685452954 0.13089115 Fuca2
## 19 10701830 0.00586885826460337 0.13089115 Hivep2
## 23 10701880 0.00749149990409956 0.13089115 Reps1Pulling just the significant genes using an adjusted p-value threshold of 0.05.
adj.pval.sig = pValue_m1[which(pValue_m1[,'padj'] < .05),]
# Viewing these genes
adj.pval.sig ## ID pval padj Gene symbol
## 5640 10783648 1.93688668590855e-06 0.01551834 Slc7a8
## 9143 10837582 4.57288413593085e-07 0.00732759 Olr633With this, we can answer Environmental Health Question 4: What genes are altered in expression by formaldehyde inhalation exposure?
Answer: Olr633 and Slc7a8.
Finally, let’s plot these using a mini heat map.
Note that we can use probesetIDs, then gene symbols, in rownames to have them show in heat map labels.
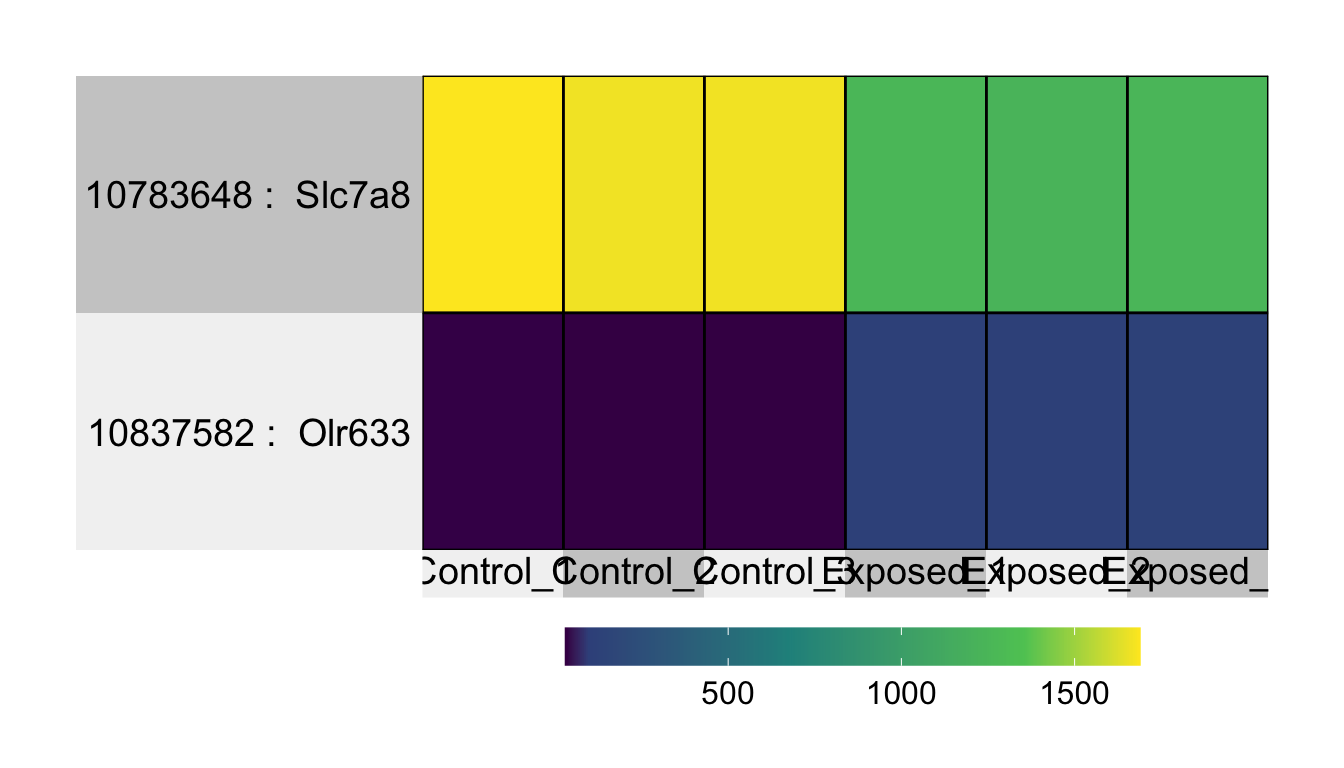
Note that this statistical filter is pretty strict when comparing only n=3 vs n=3 biological replicates. If we loosen the statistical criteria to p-value < 0.05, this is what we can find:
pval.sig = pValue_m1[which(pValue_m1[,'pval'] < .05),]
nrow(pval.sig)## [1] 53275327 genes with significantly altered expression!
Note that other filters are commonly applied to further focus these lists (e.g., background and fold change filters) prior to statistical evaluation, which can impact the final results. See Rager et al. 2013 for further statistical approaches and visualizations.
With this, we can answer Environmental Health Question 5: What are the potential biological consequences of these gene-level perturbations?
Answer: Olr633 stands for ‘olfactory receptor 633’. Olr633 is up-regulated in expression, meaning that formaldehyde inhalation exposure has a smell that resulted in ‘activated’ olfactory receptors in the nose of these exposed rats. Slc7a8 stands for ‘solute carrier family 7 member 8’. Slc7a8 is down-regulated in expression, and it plays a role in many biological processes, that when altered, can lead to changes in cellular homeostasis and disease.
Concluding Remarks
In conclusion, this training module provides an overview of pulling, organizing, visualizing, and analyzing -omics data from the online repository, Gene Expression Omnibus (GEO). Trainees are guided through the overall organization of an example high dimensional dataset, focusing on transcriptomic responses in the nasal epithelium of rats exposed to formaldehyde. Data are visualized and then analyzed using standard two-group comparisons. Findings are interpreted for biological relevance, yielding insight into the effects resulting from formaldehyde exposure.
For additional case studies that leverage GEO, see the following publications that also address environmental health questions from our research group:
Rager JE, Fry RC. The aryl hydrocarbon receptor pathway: a key component of the microRNA-mediated AML signalisome. Int J Environ Res Public Health. 2012 May;9(5):1939-53. doi: 10.3390/ijerph9051939. Epub 2012 May 18. PMID: 22754483; PMCID: PMC3386597.
Rager JE, Suh M, Chappell GA, Thompson CM, Proctor DM. Review of transcriptomic responses to hexavalent chromium exposure in lung cells supports a role of epigenetic mediators in carcinogenesis. Toxicol Lett. 2019 May 1;305:40-50. PMID: 30690063.